Build
AI Inference
Deploy and run serverless AI inference for LLMs, VLMs, embeddings, and multimodal models with an OpenAI-compatible API. Deliver faster user experiences on distributed infrastructure, with automatic scaling and no GPU clusters to manage.
Faster than traditional clouds
Tokens per second output speed
Lower latency
Low-latency inference for real-time user experiences
Keep time-to-first-token and end-to-end latency low with distributed execution. Built for interactive applications, streaming responses, and real-time decisioning.
Serverless scaling without GPU operations
Handle spiky demand without provisioning GPU clusters. Scale automatically from first request to peak load, while keeping costs aligned with usage.
Reliable by design for production workloads
Run mission-critical inference with distributed architecture and automatic failover, designed to keep AI features available when traffic spikes or regions fail.

Build, customize, and serve AI models in production
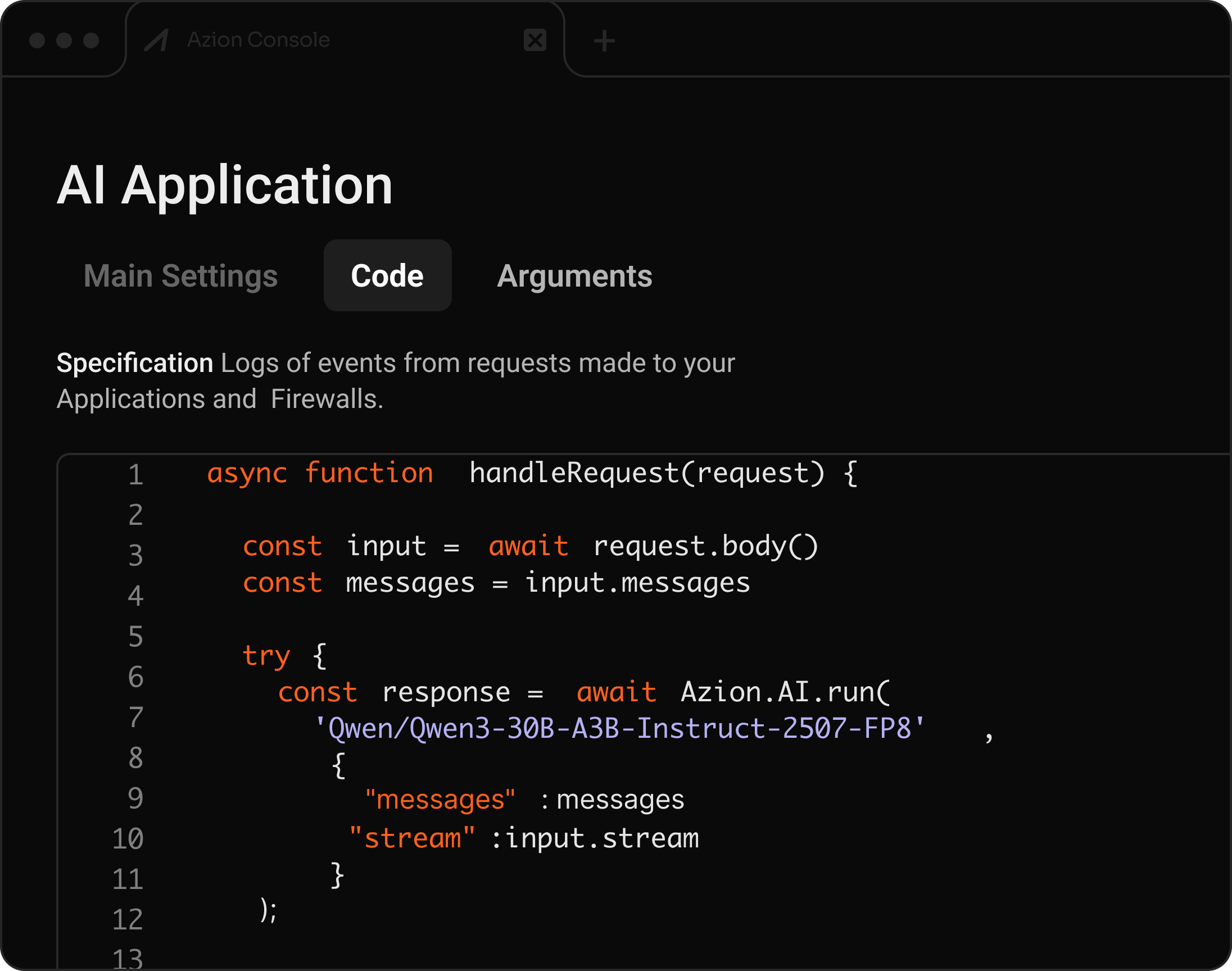
OpenAI-compatible API for serverless AI inference
Deploy production endpoints for LLMs, VLMs, embeddings, OCR, and image generation, then integrate them into Applications and Functions for distributed execution.
LLMs & VLMsFunctions integrationOpenAI-compatibleAuto-scaling
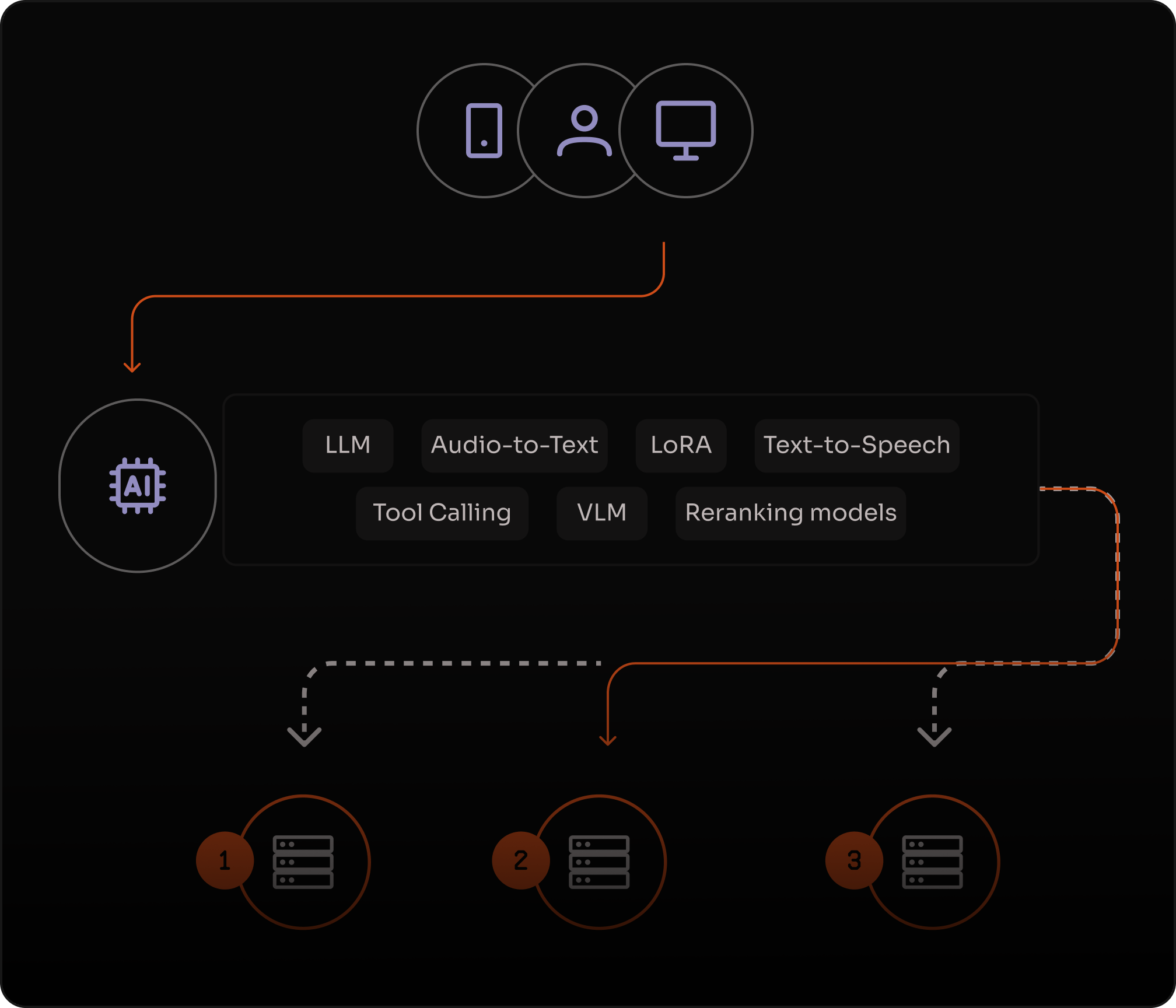
Fine-tune with LoRA for domain-specific performance
Fine-tune open-source models with Low-Rank Adaptation (LoRA) to adapt outputs to your domain without full retraining.
Improve quality for specific tasks like classification, extraction, retrieval, and support workflows while reducing compute requirements.
LoRA fine-tuningDomain customizationNo full retrainingLower compute costs
What you can build with AI Inference
Frequently Asked Questions
What is Azion AI Inference?
Azion AI Inference is a serverless platform for deploying and running AI models globally. Key features include: OpenAI-compatible API for easy migration, support for LLMs, VLMs, embeddings, and reranking, automatic scaling without GPU management, and low-latency distributed execution. Create production endpoints and integrate them into Applications and Functions.
Which models can I run?
You can choose from a catalog of open-source models available in AI Inference. The catalog includes different model types for common workloads (text and code generation, vision-language, embeddings, and reranking) and evolves as new models become available.
Is it compatible with the OpenAI API?
Yes. AI Inference supports an OpenAI-compatible API format, so you can keep your client SDKs and integration patterns and migrate by updating the base URL and credentials. See the product documentation: https://www.azion.com/en/documentation/products/ai/ai-inference/
Can I fine-tune models?
Yes. AI Inference supports model customization with Low-Rank Adaptation (LoRA), so you can specialize open-source models for your domain without full retraining. Starter guide: https://www.azion.com/en/documentation/products/guides/ai-inference-starter-kit/
How do I build RAG and semantic search?
Use AI Inference with SQL Database Vector Search to store embeddings and retrieve relevant context for Retrieval-Augmented Generation (RAG). This enables semantic search and hybrid search patterns without additional infrastructure.
Can I build AI agents and tool-calling workflows?
Yes. AI Inference can be used to power agent patterns (for example, ReAct) and tool-calling workflows when combined with Applications, Functions, and external tools. Azion also provides templates and guides for LangChain/LangGraph-based agents.
How do I deploy AI inference into my application?
Create an AI Inference endpoint and integrate it into your request flow using Applications and Functions. This lets you add AI capabilities to existing APIs and user experiences with distributed execution and managed scaling.