Despliega agentes y aplicaciones con AI en segundos
Ejecuta modelos de AI cerca de los usuarios en una infraestructura altamente distribuida para una inferencia escalable, de baja latencia y eficiente en costo, preservando la localidad de los datos.
Inferencia global en GPUs
Ejecuta inferencia serverless en tiempo real en GPU por cientos de localidades, con latencia mediana por debajo de 30 ms. Sin infraestructura para gestionar.
API compatible con OpenAI
Migra e integra capacidades de AI rápidamente con endpoints y SDK compatibles con OpenAI. Solo cambia el endpoint.
Decisión en tiempo real
Ejecuta agentes de AI estilo ReAct en una arquitectura distribuida para razonar sobre el contexto, llamar herramientas y responder en tiempo real.
La plataforma para tus workloads de AI
Construye agentes de AI
Automatiza flujos de trabajo de varios pasos con agentes de AI que razonan, planifican y actúan por ti. Reduce días de esfuerzo manual a minutos y libera a los equipos para trabajos de mayor valor.

Despliega MCP servers seguros
Conecta agentes de AI con tus herramientas, API y datos en tiempo real mediante MCP servers que se ejecutan en la misma infraestructura distribuida que tu inferencia. Protégete contra prompt injection con WAF y preserva la soberanía de los datos manteniendo el contexto dentro de la región del usuario.

Construye y escala aplicaciones con AI
Potencia tus aplicaciones ejecutando modelos de AI, fine-tuning con LoRA y pipelines de RAG con la búsqueda vectorial de SQL Database para recuperar contexto y generar respuestas fundamentadas. Convierte cualquier aplicación en una aplicación con AI con mínimo esfuerzo.

Automatiza la mitigación de amenazas
Usa AI multi-modelo para identificar phishing y patrones de abuso en tus activos digitales. Automatiza workflows de seguridad con agentic AI — desde la detección hasta el takedown.

Compatible con tu stack






Comienza rápido con templates
Construye más rápido con aplicaciones preconstruidas y starter kits para los casos de uso más comunes. Despliega proyectos completos en segundos con frameworks populares.
Next.js AI ChatbotPaint by TextLive TranscriptionTanStack AI
Opera AI con velocidad,
fiabilidad y control de costos
Ejecuta modelos de AI cerca de los usuarios
Ejecuta modelos en la infraestructura distribuida de Azion por cientos de localidades para brindar respuestas en tiempo real con latencia mediana por debajo de 30 ms.

Escala sin complicaciones, sin gestionar infraestructura
Escala workloads de AI automáticamente en una infraestructura distribuida sin gestionar servidores ni clusters.

Usa modelos preentrenados y adáptalos con LoRA
Accede a LLM, VLM, embeddings y rerankers, y luego aplica fine-tuning con LoRA usando tus datos y parámetros propios.

Paga solo cuando los modelos están en ejecución
Evita cobros por inactividad con ejecución basada en uso, pensada para operaciones de AI eficientes en costo.

Inferencia confiable en infraestructura distribuida globalmente
Mantén experiencias de AI resilientes con redundancia integrada, controles de seguridad y visibilidad en tiempo real.

Probado en combate por los mayores bancos
y empresas de e-commerce del mundo

"Con Azion, escalamos nuestros modelos de AI propietarios sin preocuparnos por la infraestructura. Inspeccionamos millones de sitios web por día y realizamos el takedown más rápido del mercado."
Fabio Ramos
CEO at Axur
Todas las primitivas de AI que necesitas
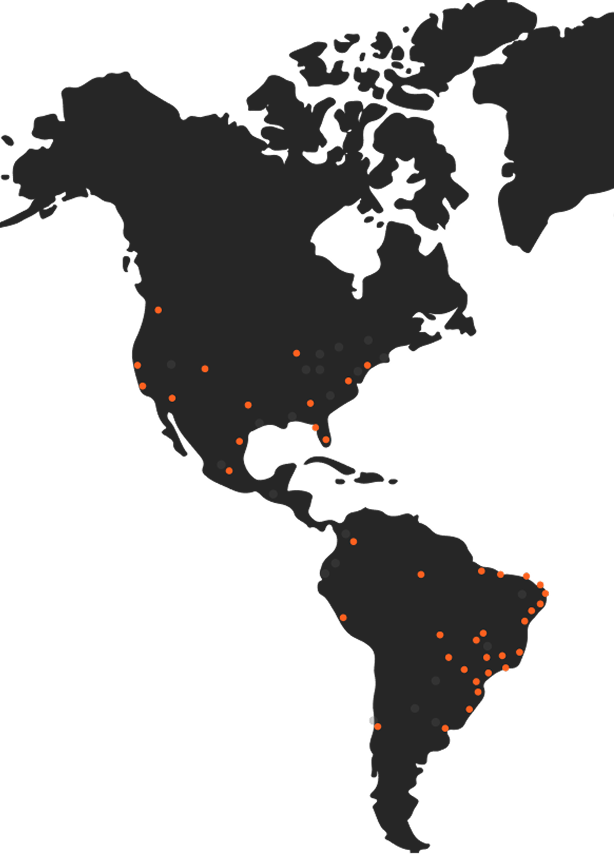
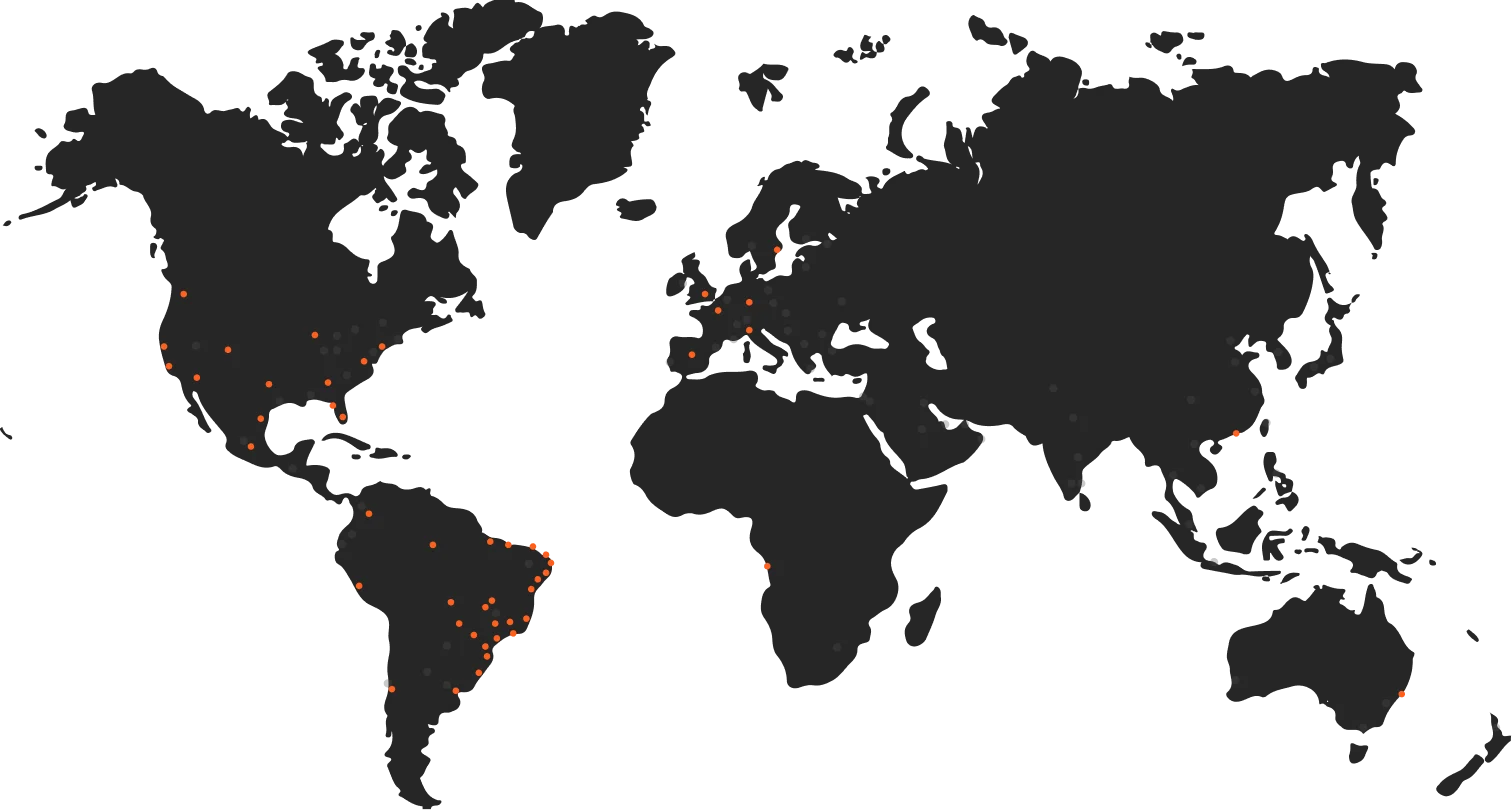
Infraestructura distribuida
que sigue en pie cuando
otras caen
100+ data centers
100+ Tbps de throughput
Escala instantánea, enrutamiento automático & failover
Latencia mediana de 30 ms
Protección contra DDoS
Compliance con PCI DSS y SOC 2/3
Resiliencia global más allá de anycast
El router global definido por software de Azion desvía el tráfico ante fallas y degradación de red más rápido de lo que BGP reconverge. Protección anti-DDoS siempre activa en más de 100 data centers.
Baja latencia en todas partes
Compute, AI, bases de datos y seguridad se ejecutan en todos los data centers, manteniendo la latencia mediana global por debajo de 30 ms, con CDN integrada y tiered caching para cada aplicación.
Autoscaling y failover cero-ops
Absorbe picos de tráfico sin cold starts, escalando de cero a millones — sin necesidad de capacity planning ni aprovisionamiento y sin costos por tiempo inactivo.
Preguntas frecuentes
¿Qué tipos de modelo son compatibles?
Azion AI Inference soporta categorías de modelos que incluyen LLM, VLM, embeddings y rerankers.Ver todos los modelos
¿Cómo uso AI Inference en mi aplicación?
Puedes llamar a AI Inference directamente desde Functions con el patrón de API `const response = await Azion.AI.run(model, input)` e integrarlo a tu flujo de solicitudes existente.
¿Azion AI es compatible con las API y SDK de OpenAI?
Sí. Azion AI Inference brinda endpoints compatibles con OpenAI, por lo que la migración suele requerir solo actualizaciones de endpoint y credenciales, en lugar de reescrituras completas.
¿Cómo implemento RAG y búsqueda semántica?
Usa AI Inference junto con la búsqueda vectorial de SQL Database para almacenar embeddings, recuperar contexto relevante y construir flujos de retrieval-augmented generation.
¿Puedo hacer fine-tuning de modelos con datos propios?
Sí. Puedes aplicar fine-tuning con LoRA a modelos preentrenados para adaptarlos y mejorar la precisión en tareas específicas para workloads de tu dominio.
¿Qué pasa si el modelo que necesito no está disponible?
Azion expande constantemente el soporte de modelos. Si necesitas un modelo específico que aún no está disponible, abre un ticket de Soporte o envía feedback a través de la Azion Console. Cada solicitud se evalúa según viabilidad técnica y demanda.
¿Cuál es la diferencia entre entrenamiento e inferencia?
El entrenamiento enseña a un modelo con datos y normalmente exige muchos recursos computacionales. La inferencia es la ejecución del modelo entrenado para generar predicciones o respuestas, y es la fase atendida por Azion AI Inference.
¿Cómo puedo monitorear el comportamiento de una aplicación de AI en producción?
Puedes monitorear solicitudes, latencia y comportamiento en tiempo de ejecución con Real-Time Metrics, Real-Time Events y API GraphQL para tener visibilidad operativa.
¿Necesito gestionar servidores o clusters para escalar?
No. Los workloads de AI escalan automáticamente en la infraestructura de Azion, incluyendo scale-to-zero y cobro basado en uso.
¿Se puede usar AI para casos de seguridad autónoma?
Sí. Puedes desplegar agentes de AI para analizar contenido en tiempo real, detectar patrones maliciosos y disparar workflows de mitigación automatizados.
Crea una vez.Ejecuta en todas partes.
Consigue una ruta más rápida al lanzamiento, menor latencia y menos sobrecarga de infraestructura.