

Introducción: Desacoplando la AI de los Datos con Model Context Protocol (MCP)
Para las empresas modernas, la latencia es una barrera inflexible para la inteligencia de la AI. Sabemos bien que la latencia de 200-500 ms de las arquitecturas centralizadas no es solo lenta, es un riesgo que drena ingresos y vuelve las estructuras vulnerables a ataques, comprometiendo los agentes de IA que prometieron transformar tu negocio. Lo que esto implica, al final de cuentas, es que la IA “en tiempo real” que te prometieron es un mito en la arquitectura de nube actual.
Los Modelos de Lenguaje de Gran Escala (LLMs) poseen un potencial inmenso, pero su estado por defecto (alucinando con base en datos propietarios y en tiempo real) compromete los ingresos e introduce riesgos inaceptables para los negocios. Esta falla significa que los LLMs desconocen las APIs internas, bases de datos activas y contextos operacionales de una organización, obligando a los desarrolladores a construir soluciones de integración muchas veces frágiles, con alto acoplamiento y código confuso, insostenible, justamente aquel que es caro y no escala.
Para enfrentar este desafío, Anthropic creó Model Context Protocol (MCP), un estándar de código abierto diseñado para funcionar como un puente universal y estandarizado entre LLMs y contextos externos. El propósito del MCP es desacoplar la IA de los datos y herramientas con los que necesita interactuar, permitiendo que cualquier cliente compatible se conecte a capacidades de IA de terceros sin integraciones personalizadas y rígidas. En esencia, el MCP funciona como un “puerto USB” para IA, proporcionando una interfaz estándar en la cual diversos componentes (como APIs internas, feeds de datos en vivo o funciones especializadas) pueden conectarse para ampliar el poder del modelo de lenguaje.
Los siguientes párrafos de este texto demuestran que implementar servidores MCP en una plataforma descentralizada y serverless como Azionofrece la arquitectura ideal para alcanzar la baja latencia, alta escalabilidad y seguridad robusta necesarias para aplicaciones de IA a nivel de producción. Al mover el punto de conexión entre el LLM (generalista) y los contextos internos (especialistas) hacia el edge de la red, las organizaciones pueden construir sistemas impulsados por IA rápidos, seguros y confiables.
Ten en cuenta que permanecer en la nube, es decir, construir otra integración personalizada y fuertemente acoplada para tu LLM, no es innovación, es deuda técnica disfrazada. Ejecutar el MCP en una región centralizada es como ponerle un motor de Ferrari a un carrito de golf. Es el equivalente al rack de servidores local de la era de la IA.
Ahora vamos a explorar los componentes fundamentales del protocolo que hacen esto posible.
Los 3 Pilares del MCP: Cómo el Protocolo le da Visión, Acción y Memoria a tu IA
Entender el diseño estratégico de la arquitectura cliente-servidor del MCP es fundamental para apreciar sus potencialidades. Esta separación de responsabilidades permite que los sistemas de IA sean más modulares, escalables y seguros.
La aplicación que contiene el LLM (el host) es diferente del servidor que proporciona acceso a sistemas externos, lo que crea una división clara para gestionar permisos y flujo de datos. En resumen, la arquitectura está compuesta por tres componentes clave:
- Host: Esta es la aplicación orientada al usuario (por ejemplo, un chatbot, un IDE de código como Cursor o una herramienta de software empresarial) que contiene el LLM y orquesta la interacción.
- Cliente: La aplicación host gestiona uno o más clientes. Cada cliente mantiene una conexión independiente y aislada con un único servidor MCP, garantizando que los contextos no se mezclen. Más que mantener conexiones, el cliente actúa como un “guardián”, impidiendo que, por ejemplo, datos de RH se mezclen con contenidos de marketing.
- Servidor: El servidor MCP es un programa independiente que actúa como un conector seguro. Proporciona contexto especializado y capacidades para la aplicación de IA al exponer una interfaz estandarizada para interactuar con sistemas externos, como bases de datos, APIs y herramientas empresariales propietarias.
Es decir, deja de construir bots “omnipotentes / god mode”, construye servidores MCP especializados que hacen una cosa a la perfección.
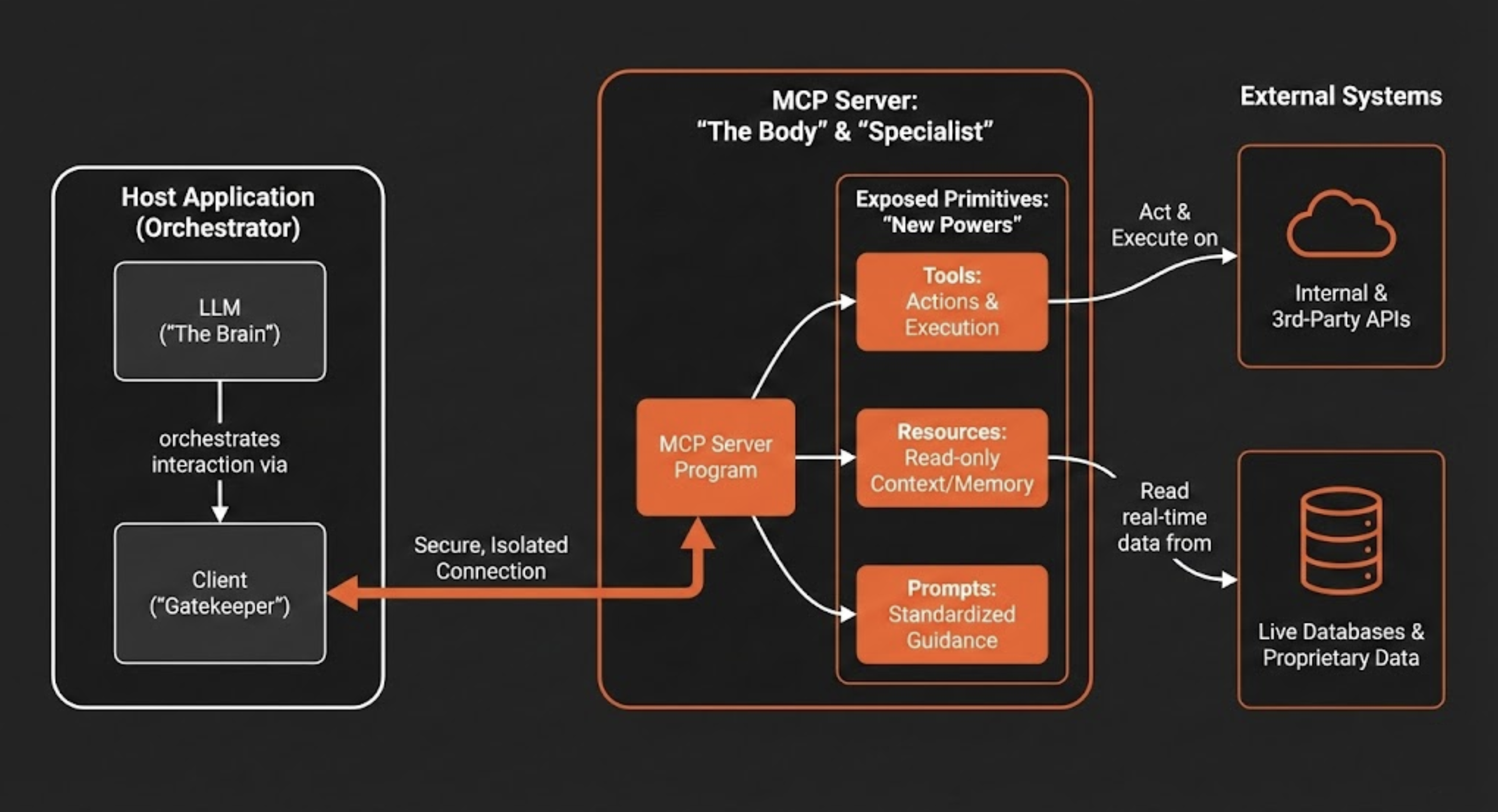
Esta arquitectura permite que un LLM acceda y utilice capacidades externas por medio de tres primitivas fundamentales que un servidor MCP expone. Estas primitivas le dan a la IA nuevos “poderes” para ver, actuar y comunicarse de manera estructurada.
Comparativamente, el host actúa como el Cerebro (Inteligencia), el Servidor es el Cuerpo (Capacidades), y las Conexiones actúan como el Sistema Nervioso. En otras palabras, un LLM sin un servidor MCP es como un cerebro en un frasco. Es inteligente, pero totalmente impotente para afectar el mundo físico.
**1. Herramientas → La diferencia entre hablar y hacer
**Las herramientas son funciones ejecutables que permiten a un LLM realizar acciones. Una herramienta puede ir desde una simple calculadora hasta un flujo de trabajo complejo que invoca APIs internas o de terceros. Cuando un LLM determina que una acción es necesaria para atender la solicitud de un usuario, puede llamar a la herramienta apropiada expuesta por el servidor MCP, como, por ejemplo, deploy_azion_static_site para orquestar una implementación, create_graphql_query para obtener datos analíticos o create_rules_engine para configurar el comportamiento de la aplicación.
**2. Recursos → La base para evitar alucinaciones
**Los recursos son fuentes de datos de solo lectura que proporcionan contexto adicional al LLM, funcionando como una memoria extendida. Su función es ofrecer la base factual necesaria para reducir “alucinaciones” del modelo. Al garantizar que las respuestas se apoyen en datos verificables, los recursos aumentan la confiabilidad de la IA. Los ejemplos incluyen el contenido de un archivo, el esquema de una base de datos, el status en tiempo real de una API o el estado actual de un pull request.
**3. Prompts → Codificando el conocimiento institucional
**Los prompts son templates, modelos predefinidos y compartidos que guían la interacción de la IA con herramientas y recursos específicos. Garantizan que las interacciones sean consistentes, de alta calidad y alineadas con los estándares organizacionales. Por ejemplo, equipos de marketing podrían usar prompts estandarizados para generar contenidos de campaña, mientras que equipos de diseño podrían usar prompts preconfigurados para crear imágenes alineadas a la marca, esto garantiza que todos usen las mismas instrucciones probadas y optimizadas.
Al comprender estos componentes centrales y las primitivas, queda claro cómo el MCP proporciona una estructura resiliente para extender la IA. La siguiente consideración crítica de este texto es dónde ejecutar esta arquitectura para maximizar su efectividad.
La Mentira de la AI “Tiempo Real” (y Cómo Arreglarlo en la Práctica)
El desempeño y la confiabilidad de una aplicación de IA dependen críticamente de la infraestructura subyacente. Aunque las arquitecturas de nube centralizadas tradicionales han sido el estándar por años, introducen un cuello de botella significativo para IA en tiempo real: latencia de red. El tiempo de ida y vuelta necesario para que los datos viajen desde el dispositivo de un usuario hasta un data center de nube distante y regresen compromete la naturaleza interactiva y responsiva que define una experiencia de IA de alta calidad. Implementar servidores MCP en la plataforma de Azionsoluciona directamente este desafío, creando el ambiente ideal para IA de alto desempeño.
**Latencia Mínima
**Al ejecutar tanto la lógica del servidor MCP como los modelos de IA directamente en edge nodes geográficamente próximos al usuario final, Azion reduce drásticamente el tiempo de ida y vuelta en la red. Mientras que endpoints de inferencia de IA hospedados en la nube alcanzan un rango de latencia mediana de 200–500ms (una eternidad para aplicaciones en tiempo real), una arquitectura que prioriza el edge y ejecuta el stack de IA completo localmente permite tiempos de respuesta por debajo de 100ms, lo cual es esencial para experiencias interactivas. Casos de uso como personalización en tiempo real, pricing dinámico y detección instantánea de fraudes, en los cuales decisiones impulsadas por la IA deben tomarse en un abrir y cerrar de ojos, se vuelven prácticas cuando tanto la capa de orquestación (MCP) como la capa de inteligencia (AI Inference) operan en el edge.
**Escalabilidad Elástica y Alta Disponibilidad
**Los workloads de IA son frecuentemente variables e impredecibles. Las Functions de Azion, junto con AI Inference, están diseñadas para escalar automáticamente y globalmente en respuesta a la demanda, garantizando que el servidor MCP pueda manejar picos repentinos de tráfico sin intervención manual o pérdida de desempeño. Esta arquitectura distribuida también proporciona alta disponibilidad inherente; si una ubicación de edge presenta un problema, el tráfico se redirige automáticamente al node saludable más cercano, manteniendo la aplicación operacional.
**Seguridad Mejorada y Soberanía de Datos
**Procesar datos sensibles en la región geográfica del usuario es una estrategia poderosa para compliance y seguridad. Esto ayuda a las organizaciones a adherirse a regulaciones de residencia de datos como GDPR y LGPD al minimizar la transmisión de datos personales más allá de las fronteras. Además, al procesar solicitudes localmente, esta arquitectura reduce la exposición al minimizar la necesidad de transmitir datos por redes públicas inseguras, disminuyendo la superficie general de ataque.
**Costo-Efectividad
**Las Functions operan en un modelo de “escalar hasta cero”, una marca registrada de la computación sin servidor. Esto significa que pagas solo por los recursos computacionales cuando tu servidor MCP está procesando activamente una solicitud. Para aplicaciones con tráfico variable o intermitente, este modelo es mucho más económico que mantener y pagar por servidores centralizados ociosos, garantizando que los costos de infraestructura se alineen directamente con el uso.
Estas ventajas arquitecturales establecen el “por qué” de ejecutar el MCP en el edge. La siguiente sección detallará el “cómo”, proporcionando una guía práctica de implementación.
Tutorial Práctico: Implementa un Servidor MCP de Alto Desempeño en Menos de 5 Minutos
Esta sección proporciona una guía práctica, paso a paso, para que los desarrolladores creen e implementen un servidor MCP funcional usando Azion Functions. El proceso ha sido simplificado para permitir implementación rápida, permitiéndote conectar tu IA a herramientas y datos externos en minutos.
**Creando la Function
**La configuración inicial se completa por medio del Console Azion con unos pasos sencillos:
- Accede al Console Azion.
- En el menú superior izquierdo, navega a la sección Functions.
- Haz clic en + Function.
- Asigna un nombre descriptivo a tu función.
- Selecciona el ambiente de ejecución Application.
- Pega el código en la pestaña Code.
Una vez creada la función, puedes implementar tu servidor MCP usando uno de los dos enfoques principales a continuación, cada uno adecuado para diferentes niveles de control y complejidad.
Opción 1: High-Level McpServer
Este enfoque es ideal para desarrollo rápido y simplicidad. La clase McpServer abstrae gran parte del código estándar, permitiéndote registrar rápidamente tus herramientas, recursos y prompts con llamadas simples.
import { Hono } from 'hono'import { StreamableHTTPServerTransport } from '@modelcontextprotocol/sdk/server/streamableHttp.js'import { toFetchResponse, toReqRes } from 'fetch-to-node'
const app = new Hono()const server = new McpServer({ name: "azion-mcp-server", version: "1.0.0"});
server.registerTool("add", { title: "Addition Tool", description: "Adds two numbers", inputSchema: { a: z.number(), b: z.number() }}, async ({ a, b }) => ({ content: [{ type: "text", text: String(a + b) }]}));
server.registerResource( "greeting", new ResourceTemplate("greeting://{name}", { list: undefined }), { title: "Greeting Resource", description: "Dynamic greeting generator" }, async (uri, { name }) => ({ contents: [{ uri: uri.href, text: `Hello, ${name}!` }] }));
app.post('/mcp', async (c: Context) => { try { const { req, res } = toReqRes(c.req.raw); const transport: StreamableHTTPServerTransport = new StreamableHTTPServerTransport({ sessionIdGenerator: undefined }); await server.connect(transport); const body = await c.req.json(); await transport.handleRequest(req, res, body); res.on('close', () => { console.log('Connection closed.'); transport.close(); server.close(); }); return toFetchResponse(res); } catch (error) { console.error('Error handling MCP request:', error); const { req, res } = toReqRes(c.req.raw); if (!res.headersSent) { res.writeHead(500).end(JSON.stringify({ jsonrpc: '2.0', error: { code: -32603, message: 'Internal server error' }, id: null, })); } }});
export default appOpción 2: Low-Level Server
Para desarrolladores que requieren un control más granular, la clase Server de bajo nivel es la opción preferida. Este enfoque es necesario para implementar lógica personalizada compleja, integrar con sistemas heredados que requieren transformaciones de datos específicas, o ajustar rutas de solicitud/respuesta críticas para el rendimiento que la abstracción de alto nivel McpServer puede ocultar. Requiere que implementes los manejadores de solicitudes para cada operación MCP directamente, otorgándote autoridad completa sobre cómo responde el servidor.
import { Hono } from 'hono';import { StreamableHTTPServerTransport } from '@modelcontextprotocol/sdk/server/streamableHttp.js';import { Server } from '@modelcontextprotocol/sdk/server/index.js';import { CallToolRequestSchema, ListToolsRequestSchema, ErrorCode, McpError,} from '@modelcontextprotocol/sdk/types.js';import { toFetchResponse, toReqRes } from 'fetch-to-node';
// 1. Define your tools manually (or fetch them from your database)const TOOLS = [ { name: "calculate_sum", description: "Adds two numbers together", inputSchema: { type: "object", properties: { a: { type: "number" }, b: { type: "number" } }, required: ["a", "b"] } }];
// 2. Initialize the Server instanceconst server = new Server({ name: 'azion-low-level-mcp', version: '1.0.0',}, { capabilities: { tools: {}, // Advertise that this server supports tools },});
// 3. Register the Handler for Listing Toolsserver.setRequestHandler(ListToolsRequestSchema, async () => { return { tools: TOOLS, };});
// 4. Register the Handler for Calling Toolsserver.setRequestHandler(CallToolRequestSchema, async (request) => { const { name, arguments: args } = request.params;
if (name === "calculate_sum") { // Runtime validation of arguments is crucial in low-level implementations if (!args || typeof args.a !== 'number' || typeof args.b !== 'number') { throw new McpError(ErrorCode.InvalidParams, "Invalid arguments for sum"); }
const result = args.a + args.b;
return { content: [{ type: "text", text: String(result) }] }; }
throw new McpError(ErrorCode.MethodNotFound, `Tool not found: ${name}`);});
const app = new Hono();
// 5. Connect the Hono HTTP adapter to the MCP Transportapp.post('/mcp', async (c) => { try { const { req, res } = toReqRes(c.req.raw);
// Create the specialized transport for streaming over HTTP const transport = new StreamableHTTPServerTransport({ sessionIdGenerator: undefined, // default });
await server.connect(transport);
// Process the JSON-RPC message await transport.handleRequest(req, res, await c.req.json());
// Cleanup when connection closes res.on('close', () => { transport.close(); server.close(); });
return toFetchResponse(res);
} catch (error) { console.error('Error handling MCP request:', error); return c.json({ jsonrpc: '2.0', error: { code: -32603, message: 'Internal server error' }, id: null }, 500); }});
export default app;Para auxiliar a desarrolladores usando el enfoque Server de bajo nivel, las tablas siguientes proporcionan una referencia rápida para los schemas de handlers de request disponibles.
Tabla 1: Schemas para Listar Propiedades
| Schema | Descripción |
|---|---|
ListToolsRequestSchema | Lista herramientas disponibles. |
ListResourcesRequestSchema | Lista recursos disponibles. |
ListPromptsRequestSchema | Lista prompts disponibles. |
Tabla 2: Schemas para Invocar Propiedades
| Schema | Descripción |
|---|---|
CallToolRequestSchema | Invoca una herramienta específica. |
ReadResourceRequestSchema | Lee datos de un recurso. |
GetPromptRequestSchema | Recupera un prompt específico. |
Con el servidor funcionando e implementado, el siguiente imperativo, por lo tanto, es garantizar que esté fortificado contra amenazas potenciales.
Seguridad de IA: Por qué tu Agente necesita una Placa, no la Contraseña del Admin
Implementar un servidor MCP requiere una postura de seguridad robusta. Como los agentes de IA pueden ejecutar acciones en nombre de un usuario, crean una nueva superficie de ataque compleja con la que modelos de seguridad tradicionales no están preparados para lidiar. El enfoque viable es el modelo Zero Trust, “nunca confíes, siempre verifica”. Cada solicitud debe ser autenticada y autorizada, independientemente del origen, garantizando protección continua.
Los principales riesgos de seguridad asociados a servidores MCP incluyen:
Inyección de Prompt: Un ataque en el que un actor malicioso incorpora instrucciones ocultas dentro de un prompt de usuario aparentemente inofensivo. Como los LLMs frecuentemente no diferencian entre instrucciones del sistema e input del usuario, estos comandos ocultos pueden engañar al modelo para realizar acciones no autorizadas, como extraer archivos sensibles o enviar correos electrónicos maliciosos.
El Problema del “Confused Deputy”: Esta vulnerabilidad surge cuando un agente de IA con privilegios elevados es engañado por un usuario con privilegios menores para usar indebidamente su autoridad. Por ejemplo, un usuario de bajo privilegio podría elaborar una solicitud que hace que una IA de alto privilegio acceda o modifique recursos que el propio usuario no debería poder alcanzar.
Ejecución No Autorizada de Comandos: Si un servidor MCP no se ejecuta en un ambiente aislado, un atacante podría explotar una vulnerabilidad para ejecutar código arbitrario en el sistema host. Esto representa una falla de seguridad crítica que podría llevar a un compromiso completo del sistema.
Para defenderse contra estas amenazas, una estrategia de seguridad de zero trust en múltiples capas es esencial. Las siguientes tácticas de mitigación forman la base de una implementación MCP segura:
- Aislar Ambientes de Ejecución: Cada servidor MCP debe ser tratado como código no confiable e implementado en un ambiente aislado (sandbox). Plataformas serverless seguras como Azion proporcionan este aislamiento por defecto, impidiendo que un servidor comprometido acceda al sistema host subyacente u otros servicios.
- Implementar Autenticación y Autorización Robustas: El acceso a herramientas, recursos y prompts debe ser estrictamente controlado. Implementar estándares modernos como OAuth para autenticación y Control de Acceso Basado en Roles (RBAC) es crítico. Esto garantiza que solo usuarios y sistemas autorizados puedan invocar herramientas específicas o acceder a datos sensibles, aplicando el principio del menor privilegio.
- Aprovechar Inteligencia de Amenazas Integrada: Una plataforma robusta debe proporcionar detección de amenazas integrada y en tiempo real. El Web Application Firewall (WAF) de Azion actúa como un perímetro defensivo crucial, inspeccionando el tráfico y bloqueando payloads maliciosos (OWASP TOP10) antes de que puedan comprometer el servidor MCP. Las Functionstambién pueden adaptarse para funcionar como una barrera programable y extensible para tus aplicaciones para promover Lógica de Seguridad Personalizada y Análisis Predictivo, por ejemplo.
Una postura de seguridad robusta protege la integridad de tus sistemas de IA. El siguiente paso es garantizar que también estén con desempeño óptimo.
Las 4 Métricas que Realmente Importan para un Agente de IA
Métricas tradicionales de desempeño de servidor, como utilización de CPU o tiempo de respuesta básico, son insuficientes para evaluar la salud y el éxito de un sistema de IA. Para servidores MCP, el éxito no es solo sobre qué tan rápido un servidor responde; es sobre la calidad, velocidad y confiabilidad de toda la interacción del usuario de punta a punta. Por lo tanto, un conjunto más completo de métricas es necesario para realmente comprender el desempeño.
Los indicadores clave de desempeño (KPIs) para una implementación saludable de servidor MCP incluyen:
- Tiempo hasta el Primer Token / Time to First Token (TTFT) Esto mide el tiempo desde cuando un usuario envía una solicitud hasta cuando la primera parte de la respuesta generada por la IA aparece. TTFT es una métrica crítica para la capacidad de respuesta percibida por el usuario, ya que un valor bajo hace que la aplicación parezca rápida e interactiva, incluso si la respuesta completa tarda más en generarse.
- Throughput Definido como el número de solicitudes o tokens que el sistema puede procesar por unidad de tiempo, el throughput es una medida de la capacidad del servidor. Alto throughput garantiza que la aplicación pueda manejar cargas pico y escalar efectivamente sin degradar el desempeño para usuarios individuales.
- Fundamentación (“Groundedness”) Esta es una métrica de calidad que evalúa qué tan bien la respuesta del modelo está respaldada por el contexto proporcionado por el servidor MCP. Alta fundamentación indica que la IA está confiando en datos factuales de sus herramientas y recursos, lo cual es el opuesto directo de un modelo “alucinando” o inventando información.
- Tasa de Finalización de Tareas Para agentes de IA diseñados para realizar tareas complejas y de múltiples etapas, esta métrica mide el porcentaje de esas tareas que se completan con éxito. Es un indicador directo de la confiabilidad y utilidad práctica del agente.
La tabla siguiente resume las métricas clave, sus importancias y objetivos de desempeño típicos para sistemas de IA implementados en una plataforma de alto desempeño.
| Métrica | Por qué importa | Objetivo Típico |
|---|---|---|
| Latencia p95 | Mantiene lentitudes pico bajo control | < 150 ms punta a punta |
| Tiempo hasta el Primer Token (TTFB) | Mejora el desempeño percibido | < 400 ms |
| Métricas de Throughput | Garantiza capacidad bajo carga | Objetivo de RPS Sostenido |
| Precisión de Búsqueda Semántica | Protege la calidad de la respuesta | 85–95% por intención |
Para rastrear efectivamente estas métricas es esencial contar con una plataforma de observabilidad robusta. Usar estándares abiertos como OpenTelemetry permite que los desarrolladores instrumenten cada componente del sistema, desde la función hasta las llamadas de base de datos, y agreguen datos de desempeño. Herramientas integradas de la plataforma como Real-Time Metrics y Data Streamde Azion proporcionan un tablero unificado para estos datos, creando una única fuente de verdad que es invaluable para solucionar cuellos de botella y garantizar una experiencia de usuario de alta calidad.
Monitorear el desempeño garantiza excelencia operacional; el paso final es ver los resultados en producción.
Conclusión: El Futuro de la IA Conectada es Distribuido (no es un Diferencial, es una Obligación)
Model Context Protocol (MCP) ha emergido como un estándar abierto esencial, proporcionando una estructura segura y escalable para conectar Modelos de Lenguaje de Gran Escala a los datos en vivo y herramientas interactivas que necesitan para ser verdaderamente efectivos. Al crear una interfaz universal, el MCP elimina la necesidad de integraciones personalizadas y frágiles y desbloquea todo el potencial de los agentes de IA para actuar como socios inteligentes en flujos de trabajo complejos.
Como este texto demostró, el poder del protocolo solo se realiza completamente cuando se implementa en una arquitectura diseñada para las demandas de la IA moderna. Una plataforma como Azion representa la mejor elección arquitectural, abordando directamente los requisitos críticos de tiempo de ida y vuelta reducido, escalabilidad elástica y seguridad robusta. Permite las interacciones por debajo de 100ms que definen aplicaciones en tiempo real, garantiza disponibilidad global y compliance con regulaciones de soberanía de datos, y proporciona un modelo operacional económico y de pago según el uso.
La combinación de MCP y computación de edge sin servidor es más que solo una solución técnica; es un habilitador estratégico. Significa que la brecha entre los líderes en el edge y aquellos que confían solo en la nube se está ampliando a cada hora. Puedes construir la infraestructura del futuro hoy o pagar la deuda técnica del pasado por los próximos 10 años.
Comienza gratis hoy o envíanos un correo a sales@azion.com.
Preguntas Frecuentes: Model Context Protocol
P: ¿Qué es Model Context Protocol (MCP)?
R: MCP es un estándar de código abierto de Anthropic que conecta LLMs a fuentes de datos externas y herramientas a través de una interfaz universal, eliminando integraciones personalizadas.
P: ¿Por qué implementar servidores MCP en el edge versus en la nube?
R: La implementación en el edge reduce la latencia de 200-500ms a <100ms, proporciona escalabilidad global automática, garantiza conformidad con GDPR y reduce costos en 70% con cobro por uso.
P: ¿Cuál es la diferencia entre herramientas y recursos del MCP?
R: Las herramientas son funciones ejecutables (acciones que la IA puede realizar). Los recursos son fuentes de datos de solo lectura (contexto que previene alucinaciones).
P: ¿Es el MCP seguro para implementaciones de IA en producción?
R: Sí, con implementación adecuada: ejecución en sandbox, autenticación OAuth, autorización RBAC, protección WAF en el edge y registro de auditoría completo.
P: ¿Cuánto tiempo toma la implementación del servidor MCP?
R: Implementación inicial: 5 minutos. Listo para producción con seguridad: 2-4 semanas siguiendo la lista de verificación de implementación.
P: ¿Cuáles son los objetivos típicos de desempeño del MCP?
R: TTFT <400ms, latencia p95 <150ms, fundamentación 85-95%, throughput sostenido correspondiendo a tus patrones de tráfico.
P: ¿Puede el MCP funcionar con cualquier LLM?
R: MCP es un estándar abierto. Cualquier cliente compatible puede conectarse a servidores MCP, aunque la calidad de la implementación varía por proveedor.
P: ¿Cuál es el ROI de la implementación MCP en el edge?
R: Mejora de latencia de 3-5x, ganancias de tasa de conversión de 23% (e-commerce), reducción de 70% en los costos de infraestructura y nuevas capacidades de IA en tiempo real anteriormente imposibles.





