La arquitectura de datos moderna requiere emparejar la herramienta correcta con cada carga de trabajo. Las bases de datos relacionales (SQL) garantizan consistencia para datos estructurados como registros financieros. Las tecnologías NoSQL—incluyendo Key-Value stores—manejan alta velocidad y esquemas flexibles para sesiones, configuraciones y características en tiempo real. Object Storage reduce costos para medios, backups y logs eliminando la complejidad jerárquica. Las bases de datos vectoriales permiten búsqueda semántica para aplicaciones de IA, potenciando sistemas de Generación Aumentada por Recuperación (RAG) que entregan respuestas precisas y conscientes del contexto.
Cada solicitud de usuario, entrega de contenido, interacción de API y log del sistema requiere persistencia o recuperación de datos. La arquitectura que elijas determina si tu aplicación responde en milisegundos o segundos, escala elegantemente o se fractura bajo carga, y controla costos o sangra presupuesto en tarifas ocultas.
Según el informe de MarketsandMarkets 2023, el mercado global de Base de Datos en la Nube y DBaaS se proyecta alcanzar USD 57.5 mil millones para 2028, creciendo a 22% anualmente—impulsado por arquitecturas distribuidas y adopción de bases de datos serverless. Este cambio refleja una transformación fundamental en cómo las aplicaciones manejan datos.
Las bases de datos tradicionales en datacenters centralizados están dando paso a arquitecturas distribuidas que procesan datos cerca de los usuarios. Este cambio no es solo sobre velocidad—se trata de habilitar nuevos patrones para aplicaciones de IA, reduciendo costos de infraestructura y manteniendo soberanía de datos a través de despliegues globales.
Las bases de datos y sistemas de almacenamiento son infraestructuras lógicas diseñadas para organizar, guardar, proteger y recuperar información digital. La diferencia radica en qué optimizan: las bases de datos destacan en consultas estructuradas y transacciones, mientras que los sistemas de almacenamiento manejan archivos crudos y datos binarios a escala.
Base de Datos vs. Almacenamiento de Archivos: ¿Cuál es la Diferencia?
Las bases de datos leen, escriben e indexan datos altamente estructurados o semi-estructurados con lógica de búsqueda refinada. Entienden relaciones entre elementos de datos, imponen restricciones y devuelven registros específicos basándose en consultas complejas.
El almacenamiento de archivos guarda archivos crudos completos—fotos, videos, backups, logs—sin procesar su estructura interna. Trata cada archivo como una unidad completa, identificado por nombre o ruta, recuperado como un todo.
Piénsalo así: una base de datos es como una hoja de cálculo donde puedes encontrar todas las filas que coinciden con criterios específicos. El almacenamiento de archivos es como un almacén donde guardas y recuperas cajas completas sin abrirlas.
Cómo la Arquitectura Distribuida Optimiza Este Flujo
Mantener datos geográficamente cerca de los usuarios en una arquitectura distribuida reduce el tiempo de round-trip (RTT). Cuando un usuario en São Paulo solicita datos, recuperarlos desde un Punto de Presencia (PoP) local toma milisegundos. Obtener los mismos datos desde un servidor centralizado en Virginia añade cientos de milisegundos—a veces segundos—a cada solicitud.
Esta latencia se compone a través de las capas de la aplicación. Una sola carga de página podría activar docenas de consultas de base de datos y recuperaciones de archivos. Cada round-trip a un datacenter distante degrada la experiencia del usuario e incrementa costos de ancho de banda.
El almacenamiento y bases de datos distribuidos resuelven esto replicando datos a través de PoPs globales, asegurando que los usuarios accedan a información desde ubicaciones cercanas en lugar de cruzar continentes.
El Ecosistema Relacional: SQL y Consistencia de Datos
¿Qué es una Base de Datos Relacional?
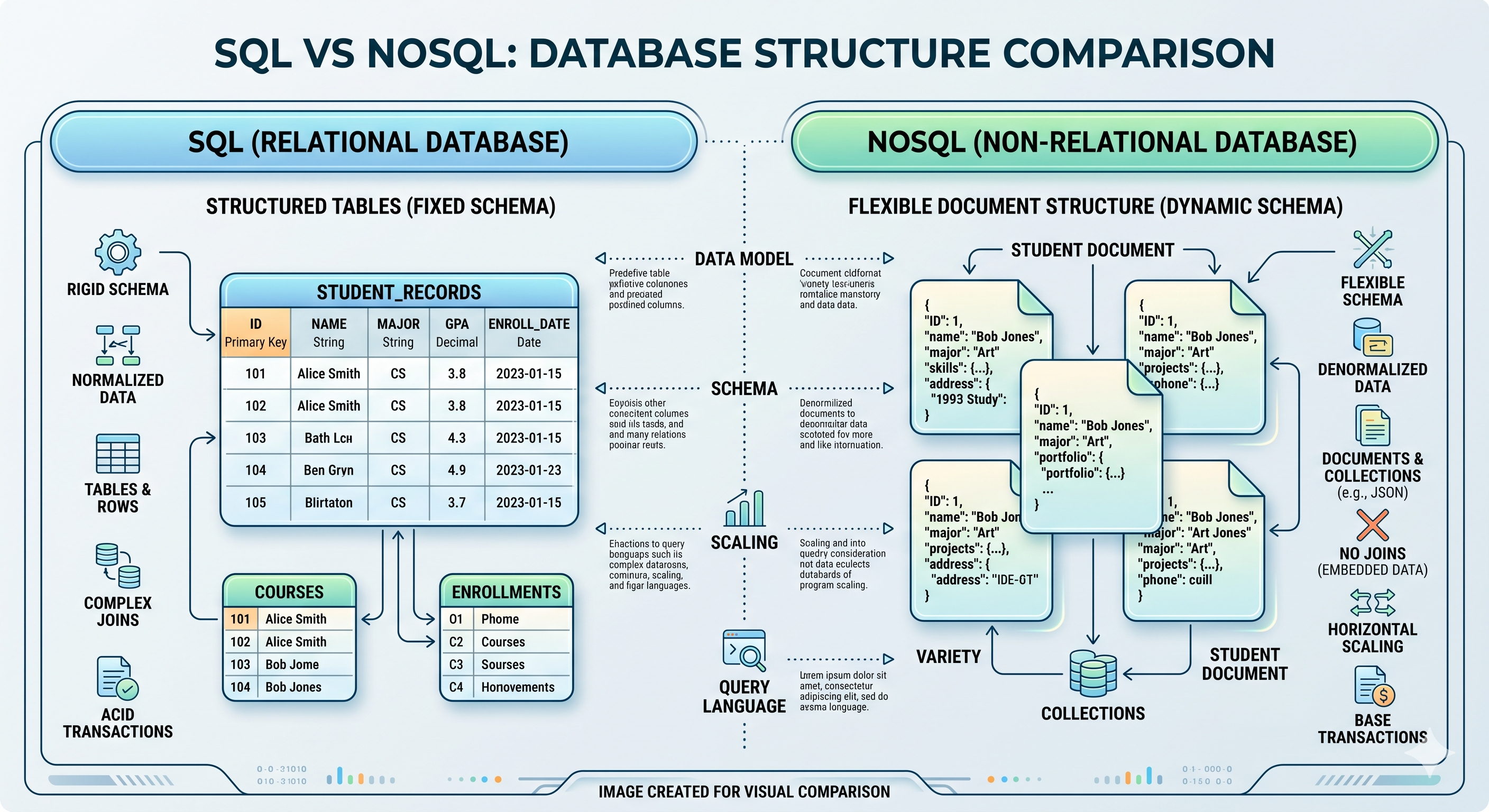
Las bases de datos SQL (Structured Query Language) organizan datos en tablas rígidas compuestas por filas y columnas, interconectadas por relaciones lógicas—claves primarias y claves foráneas. Las bases de datos relacionales imponen propiedades ACID:
- Atomicidad: Las transacciones se completan totalmente o se revierten
- Consistencia: Los datos permanecen válidos según reglas definidas
- Aislamiento: Las transacciones concurrentes no interfieren
- Durabilidad: Los datos confirmados persisten a través de fallos
Esto hace a SQL ideal para sistemas que requieren consistencia transaccional absoluta—registros financieros, gestión de inventario, autenticación de usuario y procesamiento de pedidos. Una transferencia bancaria se completa totalmente o no ocurre en absoluto. No hay término medio.
Ejemplo de transacción SQL:
-- Transferir fondos entre cuentas (transacción ACID)BEGIN TRANSACTION;
-- Debitar cuenta origenUPDATE accountsSET balance = balance - 500.00WHERE account_id = 'src_12345';
-- Acreditar cuenta destinoUPDATE accountsSET balance = balance + 500.00WHERE account_id = 'dest_67890';
-- Registrar la transferenciaINSERT INTO transfers (from_account, to_account, amount, timestamp)VALUES ('src_12345', 'dest_67890', 500.00, NOW());
-- Si algún paso falla, toda la transacción se revierteCOMMIT;SQLite: Persistencia Ligera y Autocontenida
SQLite toma un enfoque diferente. En lugar de ejecutarse como un proceso de servidor separado, opera como una biblioteca embebida directamente dentro de las aplicaciones. Toda la base de datos vive en un único archivo en disco.
Esta arquitectura hace a SQLite perfecto para:
- Aplicaciones del lado cliente que necesitan persistencia de datos local
- Funciones serverless con restricciones de memoria
- Entornos de desarrollo y pruebas
- Sistemas embebidos y dispositivos IoT
Limitaciones de SQLite a considerar: Como base de datos de archivo único, SQLite destaca en cargas de trabajo con muchas lecturas pero tiene restricciones para escrituras concurrentes. Las operaciones de escritura requieren bloqueos exclusivos en el archivo de base de datos, significando solo un escritor a la vez. En arquitecturas distribuidas, las implementaciones de SQLite típicamente usan réplicas de lectura globales con un único coordinador de escritura—ideal para aplicaciones de mayoría-lectura como entrega de contenido, preferencias de usuario o gestión de configuración, pero inadecuado para sistemas transaccionales de alto volumen.
Las arquitecturas distribuidas modernas aprovechan la portabilidad de SQLite. Las aplicaciones pueden ejecutar lógica de base de datos cerca de los usuarios, sincronizando cambios de vuelta a sistemas centrales cuando la conectividad lo permite.
SQL Distribuido: Relaciones Sin Fronteras
Las aplicaciones globales enfrentan una tensión: las bases de datos SQL destacan en consistencia, pero las instancias centralizadas crean latencia. El SQL distribuido resuelve esto replicando bases de datos relacionales a través de múltiples regiones mientras mantiene garantías ACID.
Las réplicas de lectura manejan consultas localmente, reduciendo latencia para operaciones comunes. Las operaciones de escritura se coordinan entre nodos para preservar consistencia. El resultado: los usuarios experimentan respuestas a velocidad local mientras el sistema mantiene integridad de datos globalmente.
Flexibilidad NoSQL y Velocidad de Key-Value Store
El Origen de NoSQL
Las bases de datos NoSQL (“Not Only SQL”) surgieron para manejar datos sin esquemas rígidos—documentos JSON, logs no estructurados, grafos sociales y análisis en tiempo real. Priorizan:
- Escalabilidad horizontal: Agregar capacidad añadiendo nodos, no actualizando hardware
- Esquemas flexibles: Cambiar estructura de datos sin migraciones
- Alto throughput: Optimizar para velocidad sobre consistencia estricta
- Agilidad del desarrollador: Iterar rápidamente sin sobrecarga de administración de base de datos
El Teorema CAP: La Física de los Datos Distribuidos
Al diseñar sistemas globales, los ingenieros enfrentan una restricción fundamental: el Teorema CAP. Este principio establece que un sistema distribuido solo puede garantizar dos de tres propiedades simultáneamente:
- Consistency (C): Todos los nodos ven los mismos datos al mismo tiempo
- Availability (A): Cada solicitud recibe una respuesta (éxito o fallo)
- Partition tolerance (P): El sistema continúa operando a pesar de fallos de red
Las bases de datos NoSQL diseñadas para arquitecturas distribuidas típicamente priorizan Disponibilidad y Tolerancia a partición, aceptando Consistencia Eventual como compensación. Esto significa que los datos escritos en un nodo local se vuelven inmediatamente disponibles localmente, pero las actualizaciones se propagan asíncronamente a otros nodos globales—sincronizándose completamente dentro de segundos o minutos, dependiendo de condiciones de red.
Para aplicaciones como feeds de redes sociales, carritos de compras o análisis en tiempo real, la consistencia eventual proporciona experiencia de usuario aceptable con latencia superior. Para transacciones financieras o gestión de inventario, la consistencia fuerte (SQL) permanece esencial.
Los Cuatro Modelos Fundamentales
Bases de datos de documentos almacenan datos como documentos JSON o BSON. Cada documento contiene su propia estructura, permitiendo registros heterogéneos en la misma colección. Casos de uso: gestión de contenido, perfiles de usuario, catálogos de productos.
Key-Value stores funcionan como diccionarios distribuidos. Cada item tiene una clave única (identificador) y un valor asociado (cualquier dato). Sin joins, sin consultas complejas—solo búsquedas rápidas. Casos de uso: almacenamiento de sesiones, caché, feature flags, tokens API.
Almacenes de familias de columnas organizan datos por columna en lugar de fila, optimizando para consultas analíticas que agregan campos específicos a través de millones de registros. Casos de uso: datos de series temporales, análisis, telemetría IoT.
Bases de datos de grafos mapean relaciones entre entidades como nodos y aristas. Destacan en recorrer conexiones—encontrar amigos de amigos, detectar anillos de fraude, recomendar productos. Casos de uso: redes sociales, motores de recomendación, grafos de conocimiento.
Key-Value Store: El Campeón de Velocidad para Sistemas Distribuidos
La simplicidad de la arquitectura key-value lo convierte en el modelo de base de datos más rápido para cargas de trabajo específicas. Sin joins de tablas. Sin validación de esquema. Sin parsing de consultas complejo. Solo: dame el valor para esta clave.
Ejemplo de operaciones key-value:
// Almacenar una sesión de usuarioawait kv.set('session:user_12345', { userId: 'user_12345', lastAccess: Date.now(), preferences: { theme: 'dark', lang: 'en' }}, { ttl: 3600 }); // Expira en 1 hora
// Recuperar la sesiónconst session = await kv.get('session:user_12345');
// Incrementar un contador de rate limit atómicamenteconst requests = await kv.incr('rate_limit:api:user_12345');if (requests > 100) { throw new Error('Rate limit excedido');}Esta simplicidad permite:
- Almacenamiento de sesiones: Datos de sesión de usuario recuperados en microsegundos
- Redirecciones instantáneas: Acortadores de URL y tablas de enrutamiento
- Gestión de configuración: Feature flags y configuraciones de aplicación distribuidas globalmente
- Rate limiting: Contadores para throttling de API y aplicación de cuotas
En una arquitectura distribuida, los key-value stores entregan latencia baja consistente porque el modelo de datos se alinea con la infraestructura. Las operaciones simples se completan rápidamente, incluso cuando los datos se replican a través de continentes. Los benchmarks de la industria muestran búsquedas key-value promediando 0.5-2ms en plataformas distribuidas, comparado con 50-200ms para consultas SQL complejas a través de regiones.
Object Storage y Blob Storage: Almacenando los Medios y Logs del Mundo
¿Qué es Object Storage?
A diferencia de los sistemas de archivos que organizan datos en carpetas jerárquicas, Object Storage aplana todo en un único espacio lógico—un data lake. Cada objeto tiene:
- Datos: El contenido del archivo mismo
- Metadatos: Pares clave-valor personalizados describiendo el objeto
- Identificador: Un ID único para recuperación
Esta estructura plana elimina la complejidad de jerarquías de directorios y permite escala ilimitada. Los sistemas de object storage manejan petabytes de datos sin la degradación de rendimiento que plaga a los sistemas de archivos tradicionales a escala.
Blob Storage: Datos Binarios Crudos
BLOB significa Binary Large Object. Los blobs son secuencias de bytes crudos—imágenes, videos, imágenes de contenedor, backups de base de datos, archivos de log. No requieren formateo, ni estructura, ni parsing.
Blob storage optimiza para:
- Assets de medios: Imágenes, videos, archivos de audio para aplicaciones web
- Imágenes de contenedor: Capas Docker y artefactos Kubernetes
- Archivos de backup: Volcados de base de datos, snapshots de configuración
- Almacenamiento de logs: Logs históricos para cumplimiento y análisis
La Trampa Financiera de las Tarifas de Egress
Los proveedores de nube tradicionales cobran por egress de datos—cada vez que tu aplicación lee archivos almacenados, pagas por el ancho de banda. Esto crea una estructura de costos ocultos que escala con el uso.
Considera una aplicación de medios sirviendo 10 millones de imágenes diariamente. Cada imagen de 2MB genera cargos de egress. Las matemáticas se componen rápidamente: 10 millones × 2MB = 20TB tráfico diario. En un mes de 30 días, eso son 600TB de transferencia de datos. A tasas típicas de egress de nube de $0.09 por GB, los cargos mensuales alcanzan aproximadamente $54,000—solo por recuperar tus propios datos.
Las arquitecturas distribuidas con PoPs globales reducen egress mediante caché de contenido cerca de los usuarios. Esto ha motivado la emergencia de proveedores de almacenamiento enfocados en portabilidad de datos que eliminan tarifas de egress completamente, permitiendo a las empresas mover sus archivos libremente entre nubes sin sorpresas financieras.
Bases de Datos Vectoriales: La Nueva Era de IA y RAG
¿Qué es una Base de Datos Vectorial?
Las bases de datos vectoriales almacenan y buscan embeddings—arrays numéricos generados por modelos de machine learning que representan significado semántico. En lugar de coincidir palabras clave exactas, la búsqueda vectorial encuentra contenido conceptualmente similar.
Una embedding transforma texto, imágenes o audio en un punto en espacio multidimensional. Estas embeddings son generadas por modelos de deep learning entrenados para capturar relaciones semánticas. Conceptos similares se agrupan juntos. “Auto” y “automóvil” ocupan coordenadas cercanas, aunque no compartan letras.
Embeddings y Similitud Semántica
Imagina un mapa tridimensional de conceptos. La IA posiciona ideas relacionadas cerca juntas:
- “Café” se ubica cerca de “espresso” y “cafeína”
- “Python” (el lenguaje) se agrupa con “JavaScript” y “programación”
- “Python” (la serpiente) ocupa una región diferente completamente
Esta representación espacial permite búsqueda semántica. Una consulta por “autos rápidos” recupera documentos sobre “vehículos deportivos” y “automóviles de alto rendimiento”—incluso si esas palabras exactas nunca aparecen.
Búsqueda Vectorial y RAG en Arquitectura Distribuida
La Generación Aumentada por Recuperación (RAG) combina bases de datos vectoriales con modelos de lenguaje grandes (LLMs). En lugar de depender solo de datos de entrenamiento, la IA recupera documentos relevantes de una base de datos vectorial, fundamenta su respuesta en contexto factual y genera respuestas precisas.
Ejecutar RAG en arquitectura distribuida entrega:
- Menor latencia: La búsqueda vectorial se completa cerca del usuario
- Privacidad de datos: Los documentos sensibles permanecen dentro de límites regionales
- Menor ancho de banda: Sin round-trips a servicios de IA centralizados
- Capacidad offline: Las embeddings locales permiten funcionalidad parcial sin conectividad
Esta arquitectura previene alucinaciones anclando respuestas de IA a evidencia recuperada, mientras la ejecución distribuida mantiene interacciones rápidas y privadas. Para una perspectiva más amplia sobre infraestructura de IA, consulta IA Generativa y el Continuo de Computación.
Seguridad de Datos: Endureciendo Infraestructura Extremo a Extremo
La velocidad no significa nada si las vías de datos permanecen expuestas. Mover bases de datos y lógica de IA a arquitecturas distribuidas expande la superficie de ataque—tanto física como lógica—requiriendo paradigmas de protección que se extiendan más allá de los firewalls de red tradicionales.
Ataques de Inyección: De SQL a NoSQL
La inyección SQL explota aplicaciones que concatenan entrada de usuario directamente en consultas de base de datos. Un atacante ingresa código malicioso en campos de formulario o URLs, engañando a la base de datos para ejecutar comandos no autorizados.
Ejemplo de vulnerabilidad:
-- Construcción de consulta vulnerableSELECT * FROM users WHERE username = '[entrada_usuario]'-- El atacante ingresa: ' OR '1'='1' ---- Resultado: SELECT * FROM users WHERE username = '' OR '1'='1' --'La condición inyectada '1'='1' siempre evalúa como verdadera, eludiendo la autenticación.
La inyección NoSQL varía según tecnología. En bases de datos de documentos con intérpretes internos, los atacantes inyectan expresiones lógicas u operadores de consulta específicos de ese sistema. En key-value stores simples, los ataques típicamente apuntan a manipulación de tokens de autenticación o explotación de políticas TTL (time-to-live) en lugar de inyección de consultas misma.
La prevención requiere:
- Consultas parametrizadas: Separar datos de código en comandos de base de datos
- Saneamiento de entrada: Validar y escapar todos los datos proporcionados por usuario
- Menor privilegio: Cuentas de base de datos con permisos mínimos necesarios
- Frameworks ORM: Usar bibliotecas que manejan escape automáticamente
Previniendo Vulneraciones con Arquitectura Zero Trust
Las vulneraciones de datos exponen información sensible—datos personales, credenciales, registros financieros. Zero Trust significa que el sistema nunca confía ciegamente en ninguna conexión—humana o automatizada. En arquitecturas distribuidas, esto requiere:
- Cifrado en reposo y en tránsito: Datos cifrados en disco (AES-256) y protegidos por TLS 1.3 durante transferencia de red
- Restricciones de transferencia de zona: Limitar operaciones DNS AXFR a IPs estrictamente autorizadas, previniendo fuga de topología interna
- Autenticación de servicio: Autenticación rigurosa para toda comunicación de microservicios y API, no solo endpoints面向 usuario
- Controles de acceso: Permisos basados en roles limitan quién lee qué
- Logs de auditoría: Rastrear todo acceso de datos para análisis forense
Para sistemas de IA, barreras adicionales previenen fuga de datos:
- Defensas contra inyección de prompts: Saneizar entradas a modelos de IA
- Filtrado de salida: Bloquear datos sensibles en respuestas generadas
- Límites de contexto: Limitar qué documentos pueden recuperar los sistemas de IA
Aprende más sobre seguridad para agentes de IA y mTLS para protección integral de sistemas de IA.
FAQ de Referencia Rápida
¿Qué es una base de datos relacional?
Una base de datos relacional es un sistema de almacenamiento de datos estructurado que organiza información en tablas con filas y columnas, usando SQL para consultas. Las características clave incluyen: cumplimiento ACID para consistencia transaccional, claves primarias y foráneas para relaciones, y esquemas estructurados para integridad de datos. Usa bases de datos relacionales para sistemas financieros, autenticación de usuario y gestión de inventario donde la precisión de datos es crítica.
¿Cuál es la diferencia entre blob storage y object storage?
En la práctica, estos términos frecuentemente se usan indistintamente por proveedores de nube. Estructuralmente, difieren: Blob (Binary Large Object) storage específicamente se refiere a almacenar secuencias de bytes crudos—imágenes, videos, ejecutables—sin restricciones de formato o metadatos requeridos. Object storage es la arquitectura más amplia que encapsula datos blob con una capa de indexación inteligente: identificadores únicos y metadatos personalizados enriquecidos que permiten búsqueda semántica y catalogación. Piensa en blob storage como el archivo crudo; object storage como ese archivo más etiquetas buscables y una dirección universal.
¿Cuándo debo usar SQLite vs PostgreSQL en sistemas distribuidos?
Usa SQLite cuando necesitas persistencia ligera y autocontenida: funciones serverless, aplicaciones del lado cliente, dispositivos IoT o entornos de desarrollo. Requiere configuración cero y se ejecuta como biblioteca dentro de tu aplicación.
Usa PostgreSQL (o SQL basado en servidor similar) cuando necesitas conexiones concurrentes, transacciones complejas a través de múltiples clientes o características avanzadas como stored procedures. Las bases de datos basadas en servidor manejan mejor volúmenes de escritura más altos y escenarios multi-usuario.
¿Cómo funciona la replicación de base de datos distribuida?
Las bases de datos distribuidas replican datos a través de múltiples ubicaciones geográficas usando dos patrones primarios:
- Réplicas de lectura: El nodo primario maneja escrituras; las réplicas sirven consultas de lectura localmente, reduciendo latencia para operaciones comunes
- Multi-primario: Cualquier nodo acepta escrituras; los cambios se sincronizan entre todos los nodos, permitiendo escrituras locales pero requiriendo resolución de conflictos
La replicación típicamente opera asíncronamente (consistencia eventual) o sincrónicamente (consistencia fuerte), con compensaciones entre latencia y frescura de datos.
¿Cuáles son las mejores prácticas de seguridad para bases de datos distribuidas?
- Cifrar datos en reposo y en tránsito: Usar AES-256 para datos almacenados, TLS 1.3 para comunicación de red
- Usar consultas parametrizadas: Prevenir inyección SQL separando datos de código
- Aplicar menor privilegio: Las cuentas de base de datos deben tener permisos mínimos necesarios
- Habilitar logs de auditoría: Rastrear todo acceso para análisis forense
- Implementar connection pooling: Reducir superficie de ataque limitando conexiones directas a base de datos
- Backups regulares con cifrado: Asegurar capacidad de recuperación sin exponer datos de backup
¿Qué son las tarifas de egress de datos y por qué impactan mi presupuesto?
Las tarifas de egress cobran por datos saliendo de la red de un proveedor. Cada vez que tu aplicación lee desde almacenamiento, pagas. Las matemáticas se componen: 10 millones de imágenes de 2MB diariamente = 20TB diario = 600TB mensual. A $0.09/GB, eso es aproximadamente $54,000/mes en cargos de egress. Elige proveedores que eliminen o minimicen estas tarifas, especialmente para cargas de trabajo pesadas en medios.
¿En qué difiere la búsqueda vectorial de la búsqueda tradicional por palabras clave?
La búsqueda por palabras clave coincide términos exactos. La búsqueda vectorial coincide significado semántico. Una consulta por “smartphone económico” recupera documentos sobre “dispositivos móviles accesibles” incluso sin superposición de palabras. La búsqueda vectorial reduce abandono de búsqueda en 30-40% comparado con sistemas solo de palabras clave, según benchmarks de la industria, porque los usuarios encuentran resultados relevantes incluso cuando su terminología difiere del contenido almacenado.
¿Por qué las bases de datos SQLite son populares en arquitecturas distribuidas?
SQLite no requiere proceso de servidor, almacena todo en un único archivo y se ejecuta en cualquier lugar. Esta portabilidad lo hace ideal para funciones serverless, despliegues distribuidos y aplicaciones que necesitan persistencia de datos local sin sobrecarga de infraestructura. Las bases de datos SQLite pueden copiarse, moverse y versionarse como cualquier otro archivo—simplificando despliegue y reduciendo complejidad operacional.
¿Cuál es la diferencia entre un key-value store y un caché?
Un key-value store persiste datos duraderamente—los datos escritos sobreviven reinicios y fallos. Un caché almacena datos temporalmente para rendimiento, frecuentemente con expiración TTL (time-to-live). Los cachés mejoran velocidad de lectura pero no garantizan persistencia. Usa key-value stores para datos permanentes como sesiones de usuario y feature flags; usa cachés para resultados computados accedidos frecuentemente.
¿Cuándo debo elegir NoSQL sobre SQL?
Elige NoSQL cuando:
- Tu esquema de datos evoluciona frecuentemente
- Necesitas escalado horizontal a través de muchos nodos
- La velocidad de lectura/escritura importa más que consultas complejas
- Tus datos son semi-estructurados (JSON, logs, documentos)
Elige SQL cuando:
- Las relaciones e integridad de datos son críticas
- Necesitas transacciones ACID
- Tu esquema es estable y bien definido
- Se requieren consultas complejas con joins
Consulta nuestro marco comparativo para cuándo elegir cada modelo.
Comparación de Tipos de Base de Datos
| Tipo | Mejor Para | Latencia | Escalabilidad | Ejemplos de Casos de Uso |
|---|---|---|---|---|
| SQL | Transacciones, datos estructurados | Media | Vertical | Sistemas financieros, cuentas de usuario, inventario |
| Key-Value | Sesiones, caché, configuraciones | Ultra-baja | Horizontal | Sesiones de usuario, feature flags, rate limiting |
| Documento | Esquemas flexibles, contenido | Baja | Horizontal | Catálogos de productos, perfiles de usuario, CMS |
| Object Storage | Medios, backups, logs | Baja | Ilimitada | Imágenes, videos, archivos, assets estáticos |
| Vector | IA/ML, búsqueda semántica | Media | Horizontal | Sistemas RAG, motores de recomendación, búsqueda de similitud |
Nota de rendimiento: Los key-value stores entregan búsquedas sub-milisegundo cuando se despliegan en arquitectura distribuida con datos cerca de los usuarios. La búsqueda vectorial típicamente añade 10-50ms dependiendo de dimensiones de embedding y tamaño de índice.
Conclusión
La estrategia de datos moderna no se trata de elegir una base de datos. Se trata de distribuir las tecnologías correctas de almacenamiento y base de datos a través de un continuo que empareja cada carga de trabajo.
Las bases de datos SQL garantizan consistencia para transacciones. Los sistemas NoSQL manejan velocidad y flexibilidad. Object storage gestiona escala económicamente. Las bases de datos vectoriales permiten aplicaciones de IA con comprensión semántica.
La arquitectura distribuida acerca estas tecnologías a los usuarios—reduciendo latencia, controlando costos y manteniendo soberanía de datos. A medida que la IA redefine los requisitos de las aplicaciones, la capacidad de ejecutar búsqueda vectorial, pipelines RAG y procesamiento de datos en tiempo real en Puntos de Presencia globales se convierte no solo en una optimización, sino en una necesidad competitiva.
El futuro pertenece a arquitecturas que unen latencia de microsegundos con seguridad robusta, transformando cómo almacenamos, filtramos y consultamos información globalmente.