A arquitetura de dados moderna requer combinar a ferramenta certa com cada carga de trabalho. Bancos de dados relacionais (SQL) garantem consistência para dados estruturados como registros financeiros. Tecnologias NoSQL — incluindo Key-Value stores — lidam com alta velocidade e esquemas flexíveis para sessões, configurações e recursos em tempo real. Object Storage reduz custos para mídia, backups e logs eliminando complexidade hierárquica. Bancos de dados vetoriais permitem busca semântica para aplicações de IA, potencializando sistemas de Retrieval-Augmented Generation (RAG) que entregam respostas precisas e contextuais.
Toda requisição de usuário, entrega de conteúdo, interação de API e log de sistema requer persistência ou recuperação de dados. A arquitetura que você escolhe determina se sua aplicação responde em milissegundos ou segundos, escala graciosamente ou fratura sob carga, e controla custos ou sangra orçamento em taxas ocultas.
De acordo com o relatório MarketsandMarkets 2023, o mercado global de Cloud Database e DBaaS está projetado para atingir USD 57,5 bilhões até 2028, crescendo 22% ao ano — impulsionado por arquiteturas distribuídas e adoção de bancos de dados serverless. Essa mudança reflete uma transformação fundamental em como aplicações lidam com dados.
Bancos de dados tradicionais em datacenters centralizados estão dando lugar a arquiteturas distribuídas que processam dados próximos aos usuários. Essa mudança não é apenas sobre velocidade — é sobre permitir novos padrões para aplicações de IA, reduzindo custos de infraestrutura e mantendo soberania de dados através de implantações globais.
Bancos de dados e sistemas de armazenamento são infraestruturas lógicas projetadas para organizar, salvar, proteger e recuperar informações digitais. A diferença está no que eles otimizam: bancos de dados se destacam em consultas estruturadas e transações, enquanto sistemas de armazenamento lidam com arquivos brutos e dados binários em escala.
Banco de Dados vs. Armazenamento de Arquivos: Qual é a Diferença?
Bancos de dados leem, escrevem e indexam dados altamente estruturados ou semi-estruturados com lógica de busca refinada. Eles compreendem relacionamentos entre elementos de dados, impõem restrições e retornam registros específicos baseados em consultas complexas.
Armazenamento de Arquivos salva arquivos brutos inteiros — fotos, vídeos, backups, logs — sem processar sua estrutura interna. Trata cada arquivo como uma unidade completa, identificado por nome ou caminho, recuperado como um todo.
Pense assim: um banco de dados é como uma planilha onde você pode encontrar todas as linhas que correspondem a critérios específicos. Armazenamento de arquivos é como um armazém onde você armazena e recupera caixas completas sem abri-las.
Como a Arquitetura Distribuída Otimiza Este Fluxo
Manter dados geograficamente próximos aos usuários em uma arquitetura distribuída reduz o tempo de ida e volta (RTT). Quando um usuário em São Paulo solicita dados, recuperá-los de um Ponto de Presença (PoP) local leva milissegundos. Buscar os mesmos dados de um servidor centralizado na Virgínia adiciona centenas de milissegundos — às vezes segundos — a cada requisição.
Essa latência se compõe através das camadas da aplicação. Um único carregamento de página pode disparar dezenas de consultas de banco de dados e recuperações de arquivos. Cada round-trip para um datacenter distante degrada a experiência do usuário e aumenta custos de largura de banda.
Armazenamento e bancos de dados distribuídos resolvem isso replicando dados através de PoPs globais, garantindo que usuários acessem informações de localizações próximas em vez de atravessar continentes.
O Ecossistema Relacional: SQL e Consistência de Dados
O que é um Banco de Dados Relacional?
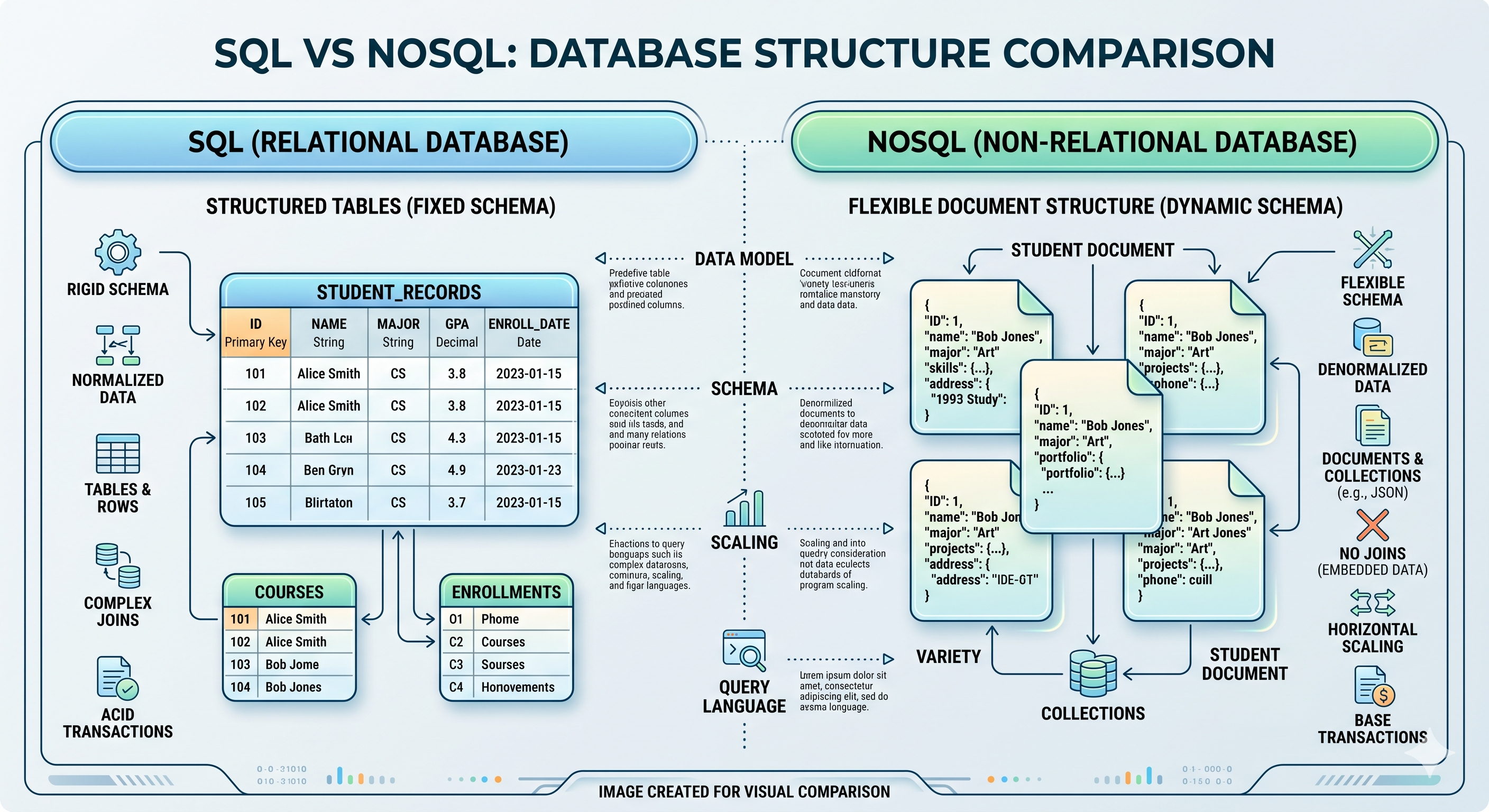
Bancos de dados SQL (Structured Query Language) organizam dados em tabelas rígidas compostas por linhas e colunas, interconectadas por relacionamentos lógicos — chaves primárias e chaves estrangeiras. Bancos de dados relacionais impõem propriedades ACID:
- Atomicidade: Transações completam inteiramente ou são revertidas
- Consistência: Dados permanecem válidos de acordo com regras definidas
- Isolamento: Transações concorrentes não interferem
- Durabilidade: Dados confirmados persistem através de falhas
Isso torna SQL ideal para sistemas que requerem consistência transacional absoluta — registros financeiros, gerenciamento de inventário, autenticação de usuário e processamento de pedidos. Uma transferência bancária ou completa totalmente ou não acontece. Não há meio termo.
Exemplo de transação SQL:
-- Transferir fundos entre contas (transação ACID)BEGIN TRANSACTION;
-- Debitar conta de origemUPDATE accountsSET balance = balance - 500.00WHERE account_id = 'src_12345';
-- Creditar conta de destinoUPDATE accountsSET balance = balance + 500.00WHERE account_id = 'dest_67890';
-- Registrar a transferênciaINSERT INTO transfers (from_account, to_account, amount, timestamp)VALUES ('src_12345', 'dest_67890', 500.00, NOW());
-- Se qualquer passo falhar, toda a transação é revertidaCOMMIT;SQLite: Persistência Leve e Autocontida
SQLite adota uma abordagem diferente. Em vez de rodar como um processo de servidor separado, opera como uma biblioteca embutida diretamente em aplicações. O banco de dados inteiro vive em um único arquivo em disco.
Essa arquitetura torna SQLite perfeito para:
- Aplicações client-side que precisam de persistência de dados local
- Funções serverless com restrições de memória
- Ambientes de desenvolvimento e teste
- Sistemas embarcados e dispositivos IoT
Limitações do SQLite a considerar: Como um banco de dados de arquivo único, SQLite se destaca em cargas de trabalho com muitas leituras, mas tem restrições para escritas concorrentes. Operações de escrita requerem bloqueios exclusivos no arquivo do banco de dados, significando apenas um escritor por vez. Em arquiteturas distribuídas, implementações SQLite tipicamente usam réplicas de leitura globais com um único coordenador de escrita — ideal para aplicações de leitura predominante como entrega de conteúdo, preferências de usuário ou gerenciamento de configuração, mas inadequado para sistemas transacionais de alto volume.
Arquiteturas distribuídas modernas aproveitam a portabilidade do SQLite. Aplicações podem executar lógica de banco de dados próxima aos usuários, sincronizando mudanças de volta a sistemas centrais quando a conectividade permite.
SQL Distribuído: Relacionamentos Sem Fronteiras
Aplicações globais enfrentam uma tensão: bancos de dados SQL se destacam em consistência, mas instâncias centralizadas criam latência. SQL distribuído resolve isso replicando bancos de dados relacionais através de múltiplas regiões enquanto mantém garantias ACID.
Réplicas de leitura lidam com consultas localmente, reduzindo latência para operações comuns. Operações de escrita coordenam entre nós para preservar consistência. O resultado: usuários experimentam respostas em velocidade local enquanto o sistema mantém integridade de dados globalmente.
Flexibilidade NoSQL e Velocidade de Key-Value Store
A Origem do NoSQL
Bancos de dados NoSQL (“Not Only SQL”) surgiram para lidar com dados sem esquemas rígidos — documentos JSON, logs não estruturados, grafos sociais e analytics em tempo real. Eles priorizam:
- Escalabilidade horizontal: Adicionar capacidade adicionando nós, não atualizando hardware
- Esquemas flexíveis: Mudar estrutura de dados sem migrações
- Alta taxa de transferência: Otimizar para velocidade em vez de consistência estrita
- Agilidade do desenvolvedor: Iterar rapidamente sem sobrecarga de administração de banco de dados
O Teorema CAP: A Física de Dados Distribuídos
Ao projetar sistemas globais, engenheiros enfrentam uma restrição fundamental: o Teorema CAP. Esse princípio afirma que um sistema distribuído pode garantir apenas duas de três propriedades simultaneamente:
- Consistência (C): Todos os nós veem os mesmos dados ao mesmo tempo
- Disponibilidade (A): Toda requisição recebe uma resposta (sucesso ou falha)
- Tolerância a partição (P): O sistema continua operando apesar de falhas de rede
Bancos de dados NoSQL projetados para arquiteturas distribuídas tipicamente priorizam Disponibilidade e Tolerância a partição, aceitando Consistência Eventual como compensação. Isso significa que dados escritos em um nó local tornam-se imediatamente disponíveis localmente, mas atualizações propagam assincronamente para outros nós globais — sincronizando completamente dentro de segundos ou minutos, dependendo das condições de rede.
Para aplicações como feeds de mídia social, carrinhos de compras ou analytics em tempo real, consistência eventual fornece experiência de usuário aceitável com latência superior. Para transações financeiras ou gerenciamento de inventário, consistência forte (SQL) permanece essencial.
Os Quatro Modelos Fundamentais
Bancos de dados de documentos armazenam dados como documentos JSON ou BSON. Cada documento contém sua própria estrutura, permitindo registros heterogêneos na mesma coleção. Casos de uso: gerenciamento de conteúdo, perfis de usuário, catálogos de produtos.
Key-Value stores funcionam como dicionários distribuídos. Cada item tem uma chave única (identificador) e um valor associado (qualquer dado). Sem joins, sem consultas complexas — apenas consultas rápidas. Casos de uso: armazenamento de sessão, caching, feature flags, tokens de API.
Column-family stores organizam dados por coluna em vez de linha, otimizando para consultas analíticas que agregam campos específicos através de milhões de registros. Casos de uso: dados de séries temporais, analytics, telemetria IoT.
Bancos de dados de grafos mapeiam relacionamentos entre entidades como nós e arestas. Eles se destacam em percorrer conexões — encontrar amigos de amigos, detectar anéis de fraude, recomendar produtos. Casos de uso: redes sociais, motores de recomendação, grafos de conhecimento.
Key-Value Store: O Campeão de Velocidade para Sistemas Distribuídos
A simplicidade da arquitetura key-value a torna o modelo de banco de dados mais rápido para cargas de trabalho específicas. Sem joins de tabelas. Sem validação de esquema. Sem parsing complexo de consultas. Apenas: me dê o valor para esta chave.
Exemplo de operações key-value:
// Armazenar uma sessão de usuárioawait kv.set('session:user_12345', { userId: 'user_12345', lastAccess: Date.now(), preferences: { theme: 'dark', lang: 'pt-br' }}, { ttl: 3600 }); // Expira em 1 hora
// Recuperar a sessãoconst session = await kv.get('session:user_12345');
// Incrementar um contador de rate limit atomicamenteconst requests = await kv.incr('rate_limit:api:user_12345');if (requests > 100) { throw new Error('Rate limit exceeded');}Essa simplicidade permite:
- Armazenamento de sessão: Dados de sessão de usuário recuperados em microssegundos
- Redirecionamentos instantâneos: Encurtadores de URL e tabelas de roteamento
- Gerenciamento de configuração: Feature flags e configurações de aplicação distribuídas globalmente
- Rate limiting: Contadores para throttling de API e imposição de quotas
Em uma arquitetura distribuída, key-value stores entregam latência baixa consistente porque o modelo de dados se alinha com a infraestrutura. Operações simples completam rapidamente, mesmo quando dados replicam através de continentes. Benchmarks da indústria mostram consultas key-value com média de 0.5-2ms em plataformas distribuídas, comparado a 50-200ms para consultas SQL complexas entre regiões.
Object Storage e Blob Storage: Armazenando a Mídia e Logs do Mundo
O que é Object Storage?
Diferente de sistemas de arquivos que organizam dados em pastas hierárquicas, Object Storage achata tudo em um único espaço lógico — um data lake. Cada objeto tem:
- Dados: O conteúdo do arquivo em si
- Metadados: Pares chave-valor personalizados descrevendo o objeto
- Identificador: Um ID único para recuperação
Essa estrutura flat elimina a complexidade de hierarquias de diretório e permite escala ilimitada. Sistemas de object storage lidam com petabytes de dados sem a degradação de performance que aflige sistemas de arquivos tradicionais em escala.
Blob Storage: Dados Binários Brutos
BLOB significa Binary Large Object. Blobs são sequências de bytes brutos — imagens, vídeos, imagens de container, backups de banco de dados, arquivos de log. Eles não requerem formatação, estrutura ou parsing.
Blob storage otimiza para:
- Assets de mídia: Imagens, vídeos, arquivos de áudio para aplicações web
- Imagens de container: Camadas Docker e artefatos Kubernetes
- Arquivos de backup: Dumps de banco de dados, snapshots de configuração
- Armazenamento de logs: Logs históricos para compliance e análise
A Armadilha Financeira das Taxas de Egress
Provedores de nuvem tradicionais cobram por egress de dados — toda vez que sua aplicação lê arquivos armazenados, você paga pela largura de banda. Isso cria uma estrutura de custos ocultos que escala com uso.
Considere uma aplicação de mídia servindo 10 milhões de imagens diariamente. Cada imagem de 2MB gera cobranças de egress. A matemática se compõe rapidamente: 10 milhões × 2MB = 20TB de tráfego diário. Ao longo de um mês de 30 dias, são 600TB de transferência de dados. A taxas típicas de egress de nuvem de $0.09 por GB, cobranças mensais atingem aproximadamente $54.000 — apenas para recuperar seus próprios dados.
Arquiteturas distribuídas com PoPs globais reduzem egress através de caching de conteúdo próximo aos usuários. Isso motivou o surgimento de provedores de armazenamento focados em portabilidade de dados que eliminam taxas de egress inteiramente, permitindo que empresas movam seus arquivos livremente entre nuvens sem surpresas financeiras.
Bancos de Dados Vetoriais: A Nova Era de IA e RAG
O que é um Banco de Dados Vetorial?
Bancos de dados vetoriais armazenam e buscam embeddings — arrays numéricos gerados por modelos de machine learning que representam significado semântico. Em vez de corresponder palavras-chave exatas, busca vetorial encontra conteúdo conceitualmente similar.
Um embedding transforma texto, imagens ou áudio em um ponto no espaço multidimensional. Esses embeddings são gerados por modelos de deep learning treinados para capturar relacionamentos semânticos. Conceitos similares se agrupam. “Carro” e “automóvel” ocupam coordenadas próximas, mesmo que não compartilhem nenhuma letra.
Embeddings e Similaridade Semântica
Imagine um mapa tridimensional de conceitos. A IA posiciona ideias relacionadas próximas umas das outras:
- “Café” fica perto de “espresso” e “cafeína”
- “Python” (a linguagem) se agrupa com “JavaScript” e “programação”
- “Python” (a cobra) ocupa uma região diferente inteiramente
Essa representação espacial permite busca semântica. Uma consulta por “carros rápidos” recupera documentos sobre “veículos esportivos” e “automóveis de alta performance” — mesmo que essas palavras exatas nunca apareçam.
Busca Vetorial e RAG em Arquitetura Distribuída
Retrieval-Augmented Generation (RAG) combina bancos de dados vetoriais com grandes modelos de linguagem (LLMs). Em vez de depender apenas de dados de treinamento, a IA recupera documentos relevantes de um banco de dados vetorial, fundamenta sua resposta em contexto factual e gera respostas precisas.
Executar RAG em arquitetura distribuída entrega:
- Menor latência: Busca vetorial completa próxima ao usuário
- Privacidade de dados: Documentos sensíveis permanecem dentro de fronteiras regionais
- Largura de banda reduzida: Sem round-trips para serviços de IA centralizados
- Capacidade offline: Embeddings locais permitem funcionalidade parcial sem conectividade
Essa arquitetura previne alucinações ancorando respostas de IA em evidência recuperada, enquanto execução distribuída mantém interações rápidas e privadas. Para uma perspectiva mais ampla sobre infraestrutura de IA, veja IA Generativa e o Continuum de Computação.
Segurança de Dados: Fortalecendo Infraestrutura de Ponta a Ponta
Velocidade não significa nada se vias de dados permanecem expostas. Mover bancos de dados e lógica de IA para arquiteturas distribuídas expande a superfície de ataque — tanto física quanto lógica — requerendo paradigmas de proteção que se estendem além de firewalls de rede tradicionais.
Ataques de Injeção: De SQL a NoSQL
SQL injection explora aplicações que concatenam entrada de usuário diretamente em consultas de banco de dados. Um atacante insere código malicioso em campos de formulário ou URLs, enganando o banco de dados para executar comandos não autorizados.
Exemplo de vulnerabilidade:
-- Construção de consulta vulnerávelSELECT * FROM users WHERE username = '[entrada_usuario]'-- Atacante insere: ' OR '1'='1' ---- Resultado: SELECT * FROM users WHERE username = '' OR '1'='1' --'A condição injetada '1'='1' sempre avalia como verdadeira, contornando autenticação.
NoSQL injection varia por tecnologia. Em bancos de dados de documentos com interpretadores internos, atacantes injetam expressões lógicas ou operadores de consulta específicos daquele sistema. Em key-value stores simples, ataques tipicamente visam manipulação de token de autenticação ou exploração de política TTL (time-to-live) em vez de injeção de consulta em si.
Prevenção requer:
- Consultas parametrizadas: Separar dados de código em comandos de banco de dados
- Sanitização de entrada: Validar e escapar todos os dados fornecidos pelo usuário
- Menor privilégio: Contas de banco de dados com permissões mínimas necessárias
- Frameworks ORM: Usar bibliotecas que lidam com escape automaticamente
Prevenindo Violações com Arquitetura Zero Trust
Violações de dados expõem informações sensíveis — dados pessoais, credenciais, registros financeiros. Zero Trust significa que o sistema nunca confia cegamente em nenhuma conexão — humana ou automatizada. Em arquiteturas distribuídas, isso requer:
- Criptografia em repouso e em trânsito: Dados criptografados em disco (AES-256) e protegidos por TLS 1.3 durante transferência de rede
- Restrições de transferência de zona: Limitar operações DNS AXFR a IPs estritamente autorizados, prevenindo vazamento de topologia interna
- Autenticação de serviço: Autenticação rigorosa para toda comunicação de microsserviço e API, não apenas endpoints voltados para o usuário
- Controles de acesso: Permissões baseadas em função limitam quem lê o quê
- Logs de auditoria: Rastrear todo acesso a dados para análise forense
Para sistemas de IA, guardrails adicionais previnem vazamento de dados:
- Defesas contra injeção de prompt: Sanitizar entradas para modelos de IA
- Filtragem de output: Bloquear dados sensíveis em respostas geradas
- Limites de contexto: Limitar quais documentos sistemas de IA podem recuperar
Saiba mais sobre segurança para agentes de IA e mTLS para proteção abrangente de sistemas de IA.
FAQ de Referência Rápida
O que é um banco de dados relacional?
Um banco de dados relacional é um sistema de armazenamento de dados estruturado que organiza informações em tabelas com linhas e colunas, usando SQL para consultas. Características principais incluem: compliance ACID para consistência transacional, chaves primárias e estrangeiras para relacionamentos, e esquemas estruturados para integridade de dados. Use bancos de dados relacionais para sistemas financeiros, autenticação de usuário e gerenciamento de inventário onde precisão de dados é crítica.
Qual é a diferença entre blob storage e object storage?
Na prática, esses termos são frequentemente usados de forma intercambiável por provedores de nuvem. Estruturalmente, eles diferem: Blob (Binary Large Object) storage refere-se especificamente a armazenar sequências de bytes brutos — imagens, vídeos, executáveis — sem restrições de formato ou metadados requeridos. Object storage é a arquitetura mais ampla que encapsula dados blob com uma camada de indexação inteligente: identificadores únicos e metadados personalizados ricos que permitem busca semântica e catalogação. Pense em blob storage como o arquivo bruto; object storage como esse arquivo mais tags pesquisáveis e um endereço universal.
Quando devo usar SQLite vs PostgreSQL em sistemas distribuídos?
Use SQLite quando você precisa de persistência leve e autocontida: funções serverless, aplicações client-side, dispositivos IoT ou ambientes de desenvolvimento. Requer configuração zero e roda como uma biblioteca dentro de sua aplicação.
Use PostgreSQL (ou SQL baseado em servidor similar) quando você precisa de conexões concorrentes, transações complexas através de múltiplos clientes ou recursos avançados como stored procedures. Bancos de dados baseados em servidor lidam melhor com volumes de escrita mais altos e cenários multi-usuário.
Como funciona replicação de banco de dados distribuído?
Bancos de dados distribuídos replicam dados através de múltiplas localizações geográficas usando dois padrões primários:
- Réplicas de leitura: Nó primário lida com escritas; réplicas servem consultas de leitura localmente, reduzindo latência para operações comuns
- Multi-primário: Qualquer nó aceita escritas; mudanças sincronizam entre todos os nós, permitindo escritas locais mas requerendo resolução de conflitos
Replicação tipicamente opera assincronamente (consistência eventual) ou sincronamente (consistência forte), com compensações entre latência e frescor dos dados.
Quais são as melhores práticas de segurança para bancos de dados distribuídos?
- Criptografar dados em repouso e em trânsito: Usar AES-256 para dados armazenados, TLS 1.3 para comunicação de rede
- Usar consultas parametrizadas: Prevenir SQL injection separando dados de código
- Aplicar menor privilégio: Contas de banco de dados devem ter permissões mínimas necessárias
- Habilitar logs de auditoria: Rastrear todo acesso para análise forense
- Implementar connection pooling: Reduzir superfície de ataque limitando conexões diretas ao banco de dados
- Backups regulares com criptografia: Garantir capacidade de recuperação sem expor dados de backup
O que são taxas de egress de dados e por que impactam meu orçamento?
Taxas de egress cobram por dados saindo da rede de um provedor. Toda vez que sua aplicação lê do armazenamento, você paga. A matemática se compõe: 10 milhões de imagens de 2MB diariamente = 20TB diários = 600TB mensais. A $0.09/GB, isso é aproximadamente $54.000/mês em cobranças de egress. Escolha provedores que eliminam ou minimizam essas taxas, especialmente para cargas de trabalho pesadas em mídia.
Como busca vetorial difere de busca por palavra-chave tradicional?
Busca por palavra-chave corresponde termos exatos. Busca vetorial corresponde significado semântico. Uma consulta por “smartphone econômico” recupera documentos sobre “dispositivos móveis acessíveis” mesmo sem sobreposição de palavras. Busca vetorial reduz abandono de busca em 30-40% comparado a sistemas apenas por palavra-chave, de acordo com benchmarks da indústria, porque usuários encontram resultados relevantes mesmo quando sua terminologia difere do conteúdo armazenado.
Por que bancos de dados SQLite são populares em arquiteturas distribuídas?
SQLite não requer processo de servidor, armazena tudo em um único arquivo e roda em qualquer lugar. Essa portabilidade o torna ideal para funções serverless, implantações distribuídas e aplicações que precisam de persistência de dados local sem sobrecarga de infraestrutura. Bancos de dados SQLite podem ser copiados, movidos e versionados como qualquer outro arquivo — simplificando implantação e reduzindo complexidade operacional.
Qual é a diferença entre um key-value store e um cache?
Um key-value store persiste dados de forma durável — dados escritos sobrevivem a reinicializações e falhas. Um cache armazena dados temporariamente para performance, frequentemente com expiração TTL (time-to-live). Caches melhoram velocidade de leitura mas não garantem persistência. Use key-value stores para dados permanentes como sessões de usuário e feature flags; use caches para resultados computados frequentemente acessados.
Quando devo escolher NoSQL em vez de SQL?
Escolha NoSQL quando:
- Seu esquema de dados evolui frequentemente
- Você precisa de escalabilidade horizontal através de muitos nós
- Velocidade de leitura/escrita importa mais que consultas complexas
- Seus dados são semi-estruturados (JSON, logs, documentos)
Escolha SQL quando:
- Relacionamentos e integridade de dados são críticos
- Você precisa de transações ACID
- Seu esquema é estável e bem definido
- Consultas complexas com joins são necessárias
Confira nosso framework comparativo quando escolher cada modelo.
Comparação de Tipos de Banco de Dados
| Tipo | Melhor Para | Latência | Escalabilidade | Exemplos de Caso de Uso |
|---|---|---|---|---|
| SQL | Transações, dados estruturados | Média | Vertical | Sistemas financeiros, contas de usuário, inventário |
| Key-Value | Sessões, caching, configurações | Ultra-baixa | Horizontal | Sessões de usuário, feature flags, rate limiting |
| Documento | Esquemas flexíveis, conteúdo | Baixa | Horizontal | Catálogos de produtos, perfis de usuário, CMS |
| Object Storage | Mídia, backups, logs | Baixa | Ilimitada | Imagens, vídeos, arquivos, assets estáticos |
| Vetorial | IA/ML, busca semântica | Média | Horizontal | Sistemas RAG, motores de recomendação, busca de similaridade |
Nota de performance: Key-value stores entregam consultas sub-milissegundo quando implantados em arquitetura distribuída com dados próximos aos usuários. Busca vetorial tipicamente adiciona 10-50ms dependendo das dimensões do embedding e tamanho do índice.
Conclusão
Estratégia moderna de dados não é sobre escolher um banco de dados. É sobre distribuir as tecnologias certas de armazenamento e banco de dados através de um continuum que corresponde a cada carga de trabalho.
Bancos de dados SQL garantem consistência para transações. Sistemas NoSQL lidam com velocidade e flexibilidade. Object storage gerencia escala economicamente. Bancos de dados vetoriais permitem aplicações de IA com compreensão semântica.
A arquitetura distribuída traz essas tecnologias próximas aos usuários — reduzindo latência, controlando custos e mantendo soberania de dados. Conforme IA remodela requisitos de aplicações, a capacidade de executar busca vetorial, pipelines RAG e processamento de dados em tempo real em Pontos de Presença globais torna-se não apenas uma otimização, mas uma necessidade competitiva.
O futuro pertence a arquiteturas que unem latência de microssegundos com segurança robusta, transformando como armazenamos, filtramos e consultamos informações globalmente.
Tópicos Relacionados
Continue explorando o cluster Storage e Database:
- O que é um Banco de Dados Relacional? — SQL, propriedades ACID e dados estruturados
- O que é NoSQL e Key-Value Store? — Bancos de dados não relacionais explicados
- O que é Object Storage e Blob Storage? — Armazenamento de dados não estruturados em escala
- O que é um Banco de Dados Vetorial? — O cérebro das aplicações de IA
- O que é Segurança de Banco de Dados? — SQL injection e prevenção de violações