Construir
AI Inference
Despliega y ejecuta inferencia de AI serverless para LLMs, VLMs, embeddings y modelos multimodales con una API compatible con OpenAI. Entrega experiencias de usuario más rápidas en infraestructura distribuida, con escalado automático y sin clusters de GPU para gestionar.
Más rápido que clouds tradicionales
Tokens por segundo de velocidad de salida
Menor latencia
Inferencia de baja latencia para experiencias de usuario en tiempo real
Mantén time-to-first-token y latencia end-to-end bajos con ejecución distribuida. Construido para aplicaciones interactivas, respuestas en streaming y toma de decisiones en tiempo real.
Escalado serverless sin operaciones de GPU
Maneja demanda variable sin provisionar clusters de GPU. Escala automáticamente desde la primera solicitud hasta el pico de carga, manteniendo costes alineados con el uso.
Confiable por diseño para workloads de producción
Ejecuta inferencia mission-critical con arquitectura distribuida y failover automático, diseñado para mantener recursos de AI disponibles cuando el tráfico aumenta o regiones fallan.

"Con Azion, podemos escalar nuestros modelos de IA propietarios sin tener que preocuparnos por la infraestructura. Estas soluciones inspeccionan millones de sitios web diariamente, detectando y neutralizando amenazas con rapidez y precisión, realizando el takedown más rápido del mercado."
Fabio Ramos
CEO
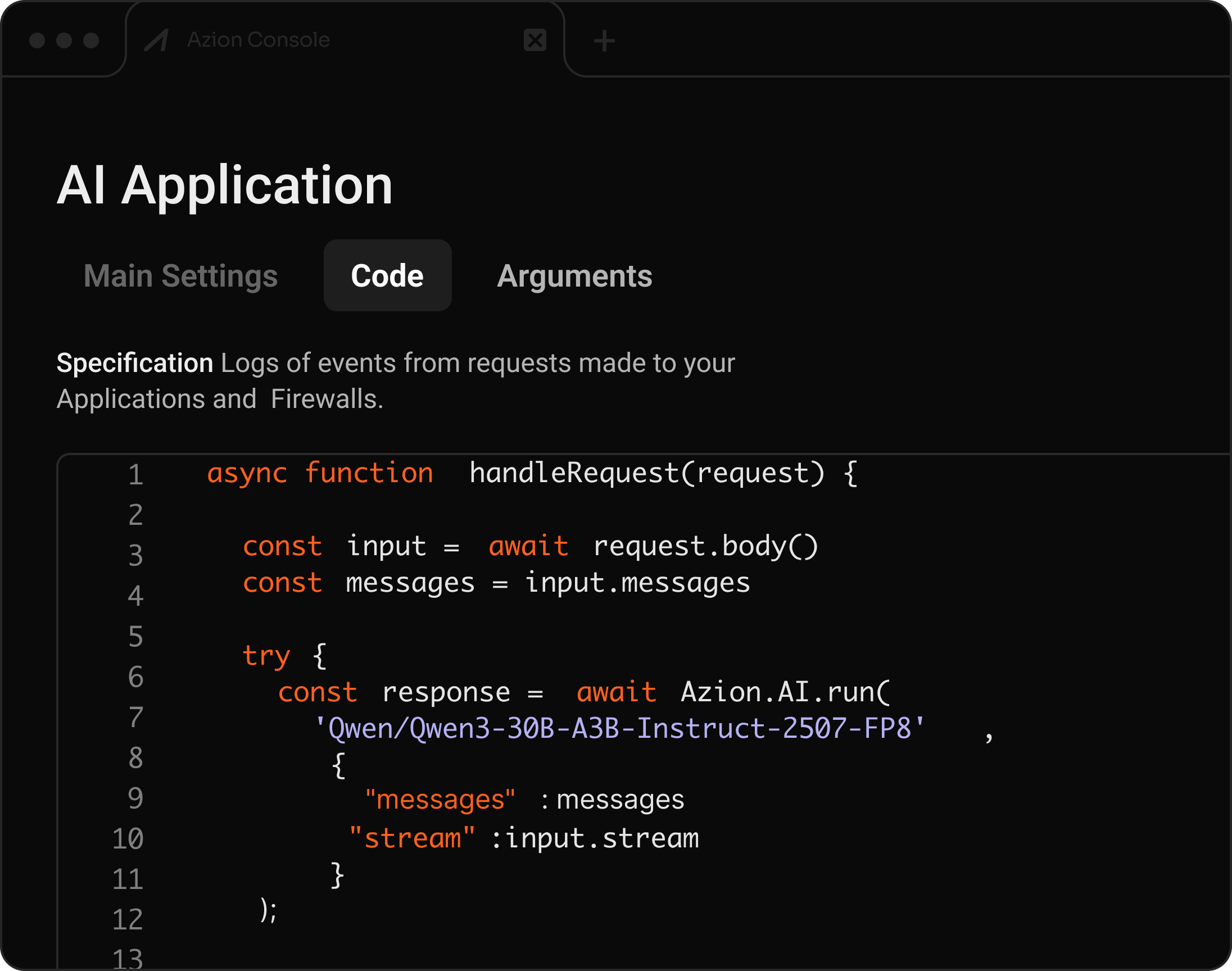
Construye, personaliza y sirve modelos de AI en producción
API compatible con OpenAI para inferencia de AI serverless
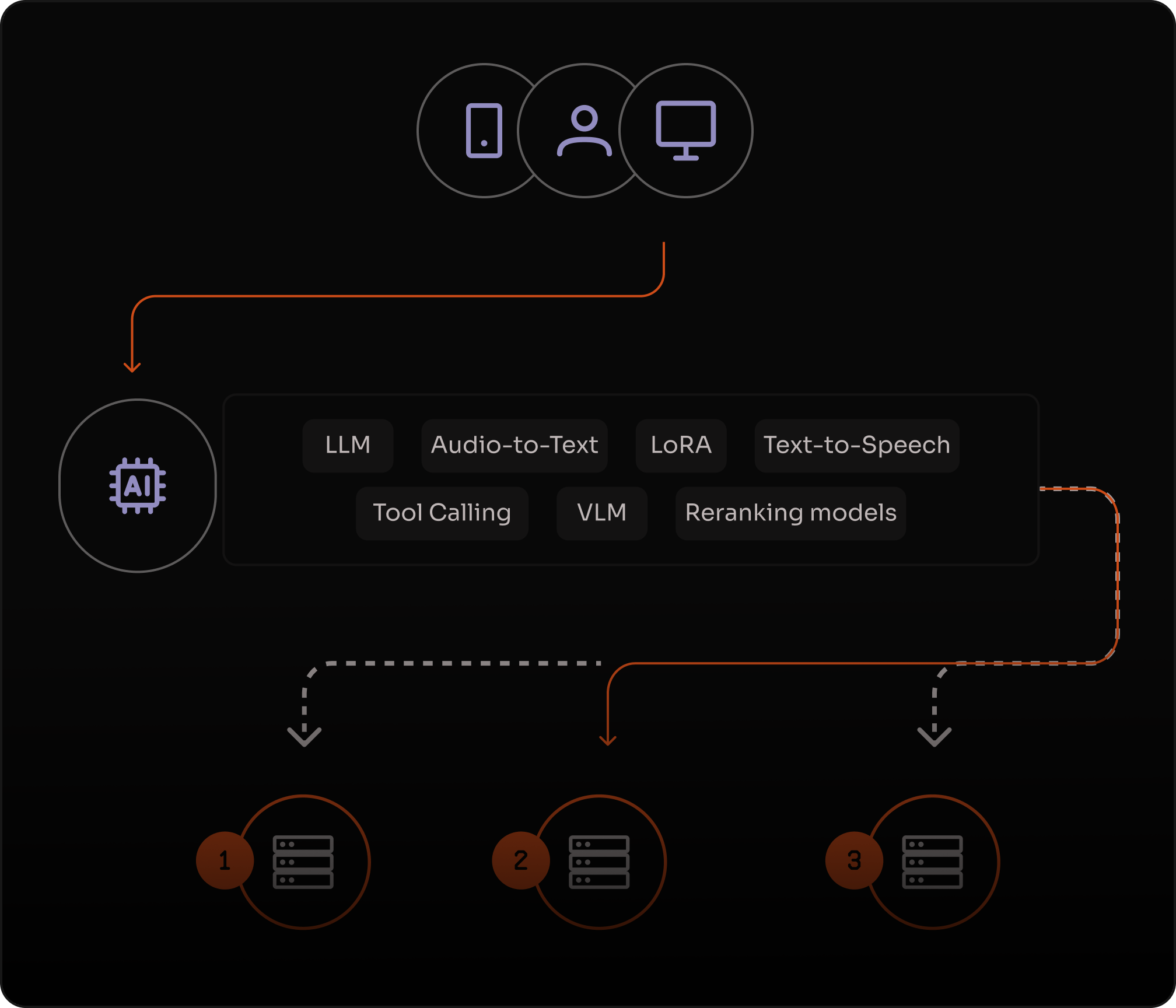
Despliega y ejecuta LLMs, VLMs, Embeddings, Audio a Texto, Texto a Imagen, Tool Calling, LoRA, Rerank y LLMs de codificación — todo integrado con aplicaciones distribuidas.
LLMs & VLMsIntegración FunctionsCompatible con OpenAIAuto-scaling
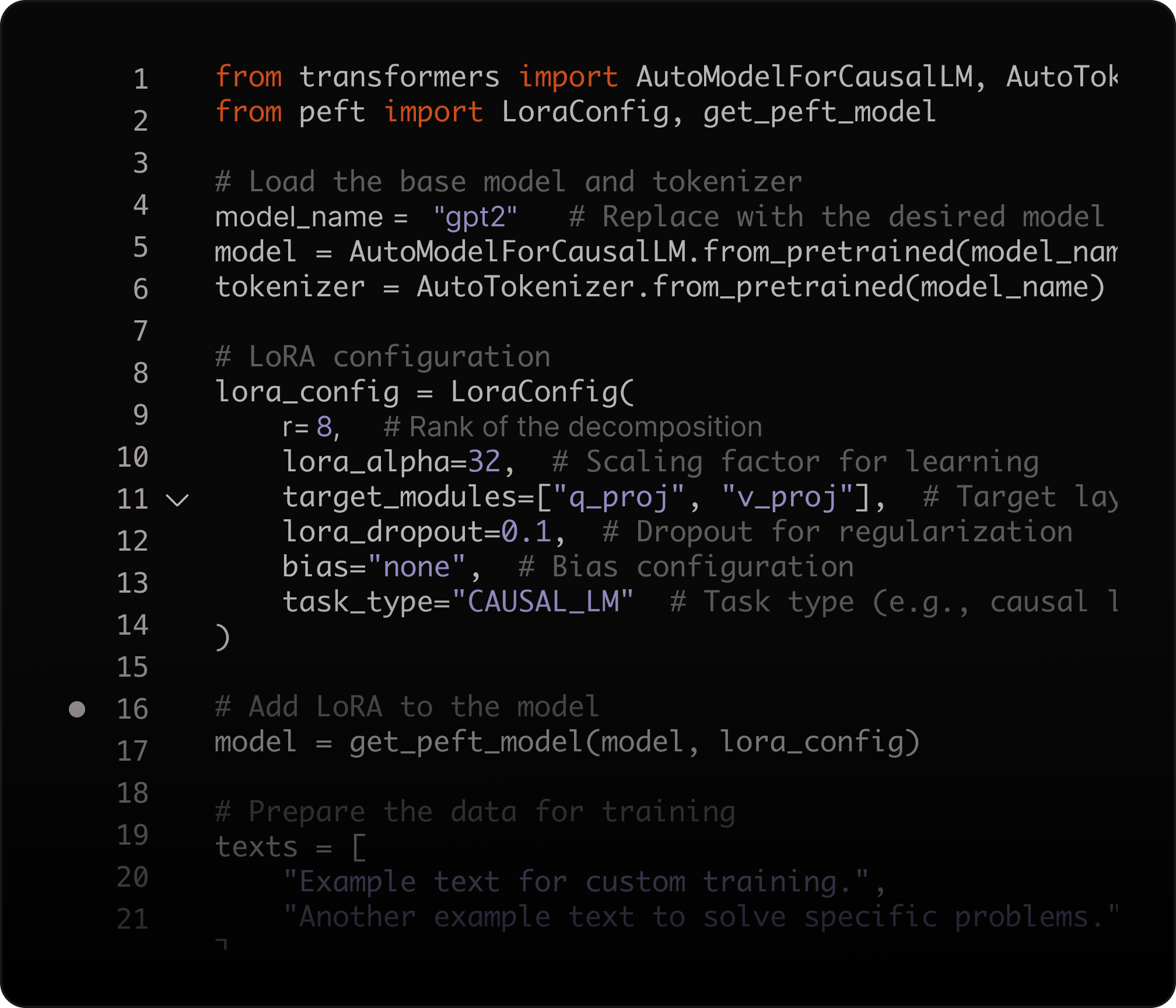
Fine-tune con LoRA para rendimiento específico de dominio
Afina modelos de AI con Low-Rank Adaptation (LoRA) para personalizar inferencias, optimizar el rendimiento y reducir los costes de entrenamiento.
Ajusta parámetros de forma eficiente y resuelve problemas complejos con un menor uso de recursos.
Fine-tuning LoRAPersonalización de dominioSin reentrenamiento completoMenor coste de cómputo
Qué puedes construir con AI Inference
Preguntas Frecuentes
¿Qué es Azion AI Inference?
Azion AI Inference es una plataforma serverless para desplegar y ejecutar modelos de AI globalmente. Características principales incluyen: API compatible con OpenAI para migración fácil, soporte a LLMs, VLMs, embeddings y reranking, escalado automático sin gestión de GPU, y ejecución distribuida de baja latencia. Crea endpoints de producción e intégralos en Applications y Functions.
¿Qué modelos puedo ejecutar?
Puede elegir de un catálogo de modelos de código abierto disponibles en AI Inference. El catálogo incluye diferentes tipos de modelos para cargas de trabajo comunes (generación de texto y código, vision-language, embeddings y reranking) y evoluciona a medida que nuevos modelos están disponibles.
¿Es compatible con la API de OpenAI?
Sí. AI Inference soporta un formato de API compatible con OpenAI, por lo que puede mantener sus SDKs de cliente y patrones de integración y migrar actualizando la URL base y las credenciales. Consulte la documentación del producto: https://www.azion.com/es/documentacion/productos/ai/ai-inference/
¿Puedo hacer fine-tuning de modelos?
Sí. AI Inference soporta personalización de modelos con Low-Rank Adaptation (LoRA), para que pueda especializar modelos de código abierto para su dominio sin reentrenamiento completo. Guía inicial: https://www.azion.com/es/documentacion/productos/guias/ai-inference-starter-kit/
¿Cómo construyo RAG y búsqueda semántica?
Use AI Inference con SQL Database Vector Search para almacenar embeddings y recuperar contexto relevante para Retrieval-Augmented Generation (RAG). Esto permite patrones de búsqueda semántica y búsqueda híbrida sin infraestructura adicional.
¿Puedo construir AI agents y workflows con tool-calling?
Sí. AI Inference puede usarse para alimentar patrones de agentes (por ejemplo, ReAct) y workflows con tool-calling cuando se combina con Applications, Functions y herramientas externas. Azion también proporciona plantillas y guías para agentes basados en LangChain/LangGraph.
¿Cómo despliego AI inference en mi aplicación?
Cree un endpoint de AI Inference e intégrelo en su flujo de solicitudes usando Applications y Functions. Esto le permite agregar capacidades de AI a APIs existentes y experiencias de usuario con ejecución distribuida y escalado gestionado.