Preview
SQL Database
Escala sin esfuerzo y potencia el rendimiento global de tu aplicación con nuestra base de datos SQL distribuida y serverless.






























Lecturas globales, latencia local
Réplicas cerca de los usuarios reducen RTT y aceleran consultas SQL, manteniendo los datos cerca de quien los consume.
Resiliencia integrada
Replicación continua y failover automático mantienen tus aplicaciones en línea con alta disponibilidad.
Eficiencia de costos
Paga por almacenamiento y operaciones; las lecturas distribuidas alivian tu aplicación y reducen gastos.


"Nuestra asociación con Azion transformó nuestras operaciones. Redujimos costos y mejoramos el rendimiento, recuperando más de 200 horas mensuales para enfocarnos en desarrollo estratégico."
Mateus Leonardi
CTO en HeroSpark
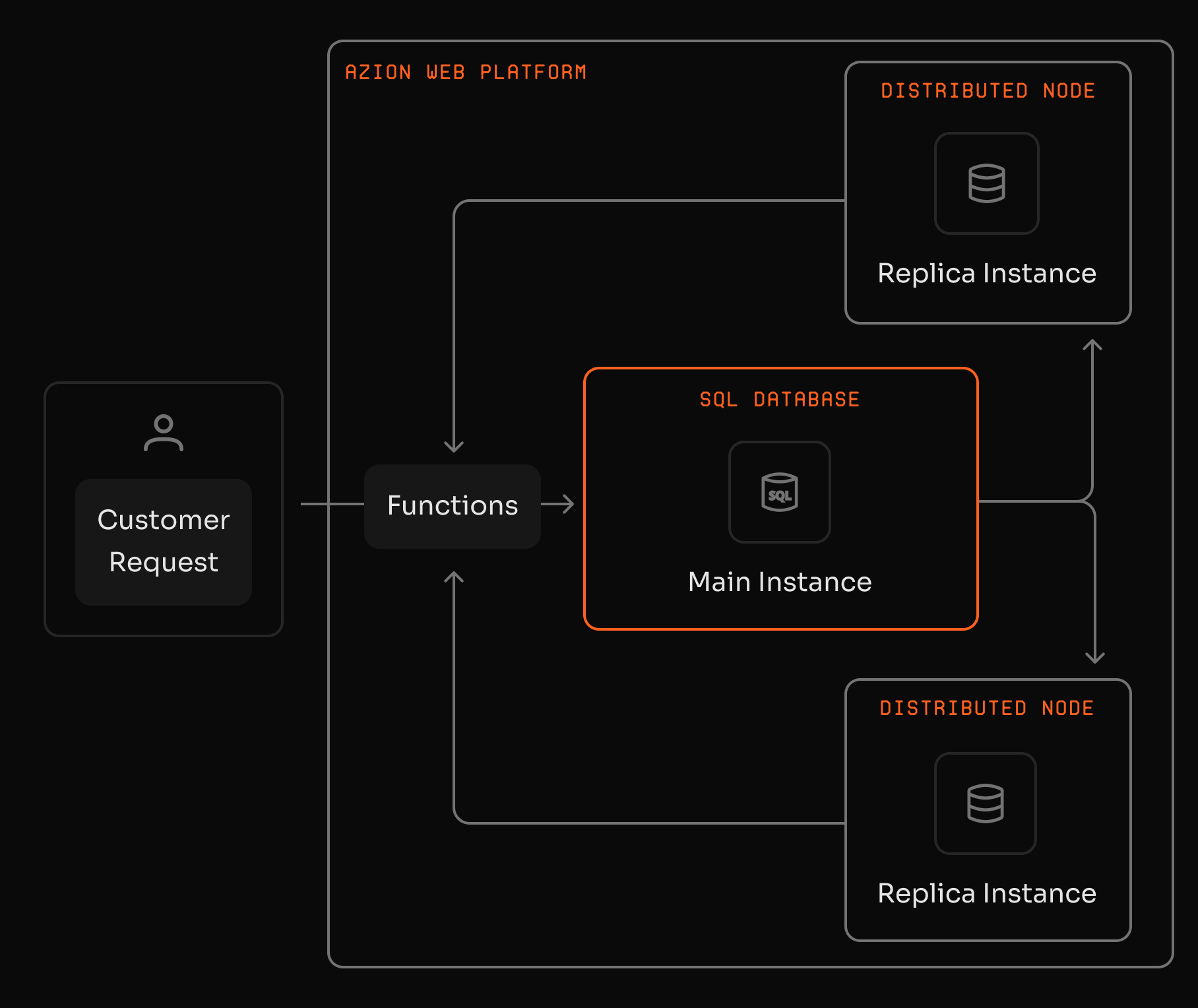
SQL distribuido con lecturas globales en milisegundos
La instancia principal procesa escrituras mientras las réplicas globales atienden lecturas, reduciendo la latencia y evitando la sobrecarga en la aplicación.
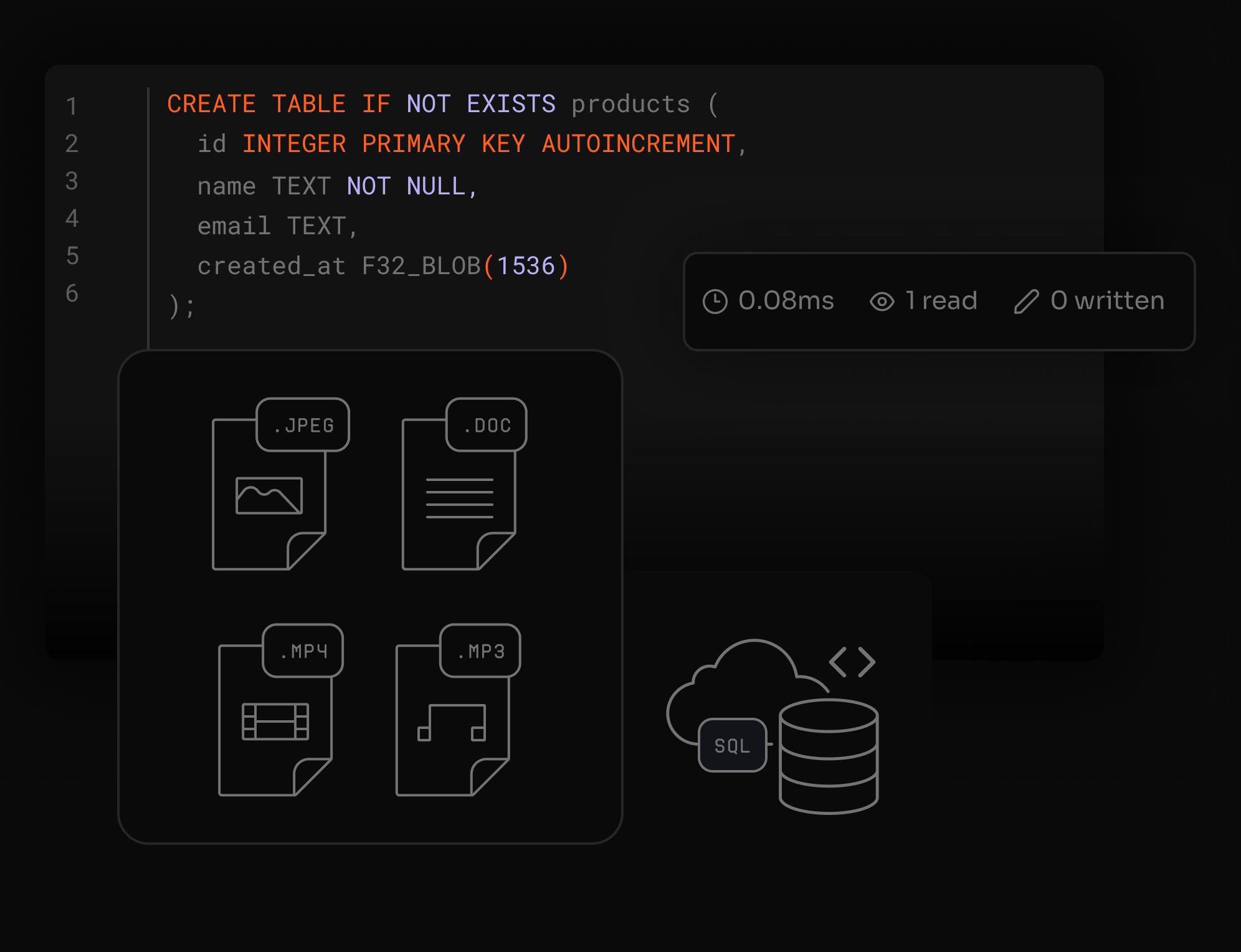
LibSQL con búsqueda vectorial integrada
Ejecuta consultas relacionales y vectoriales en la misma base de datos, permitiendo RAG, recomendación y clasificación con baja latencia.
Vea cómo usar
Preguntas Frecuentes
¿Qué es SQL Database?
Azion SQL Database es una solución SQL serverless y distribuida. Características principales incluyen: latencia de lectura sub-20ms de réplicas globales, conformidad ACID en la instancia principal, compatibilidad SQLite/libSQL, búsqueda vectorial con hasta 65.536 dimensiones, e integración nativa con Functions. Crea apps RAG, sistemas de autenticación y APIs de baja latencia.
¿Cómo replica datos SQL Database?
SQL Database usa una arquitectura Main/Replicas. Las escrituras ocurren en la instancia principal y los datos se propagan a réplicas de lectura en la infraestructura distribuida.
¿Puedo escribir en las réplicas?
No. Las réplicas son de solo lectura. Escribir datos solo es posible en la instancia principal, ya sea vía API REST o vía Functions.
¿Las réplicas son inmediatamente consistentes con la instancia principal?
No. Las réplicas se actualizan con un tiempo de propagación, por lo que eventualmente se sincronizan con la instancia principal en lugar de actualizarse instantáneamente.
¿Cómo consulto SQL Database desde Functions?
Functions pueden abrir una conexión a una réplica de lectura y ejecutar queries y comandos SQL. Esto es útil para lecturas de baja latencia y decisiones en tiempo de solicitud.
¿Puedo gestionar bases de datos con una API?
Sí. Puede crear, listar, consultar y eliminar bases de datos usando la API REST de SQL Database. La creación de la base de datos puede tardar unos minutos antes de estar lista para usar.
¿Qué sucede si elimino una base de datos?
Eliminar una base de datos no se puede deshacer. Después de la eliminación, ya no puede leer ni escribir en esa base de datos.
¿Cuáles son los límites predeterminados para SQL Database?
Los límites predeterminados incluyen hasta 100 columnas por tabla y duración máxima de query SQL de 30 segundos. El conteo de bases de datos y límites de almacenamiento dependen de su plan de servicio.
¿Qué es Vector Search en SQL Database?
Vector Search permite búsqueda semántica usando embeddings vectoriales almacenados en SQL Database. Soporta cálculos de distancia coseno e indexación para queries de vecino más cercano aproximado.
¿Existe un límite en las dimensiones de vectores?
Sí. Las operaciones vectoriales pueden realizarse en vectores con hasta 65.536 dimensiones.
Tus datos.Disponibles en todas partes.
Consigue acceso más rápido, escalado más simple y menos sobrecarga de almacenamiento a medida que crecen los datos.