
En nuestro último artículo explicamos cómo fue incorporado JAMStack en el sitio web de Azion. Ahora hablaremos sobre los resultados de pequeñas acciones en la optimización del número de recursos usados, lo que llevó a una mejora en el tiempo de carga de las más de 900 páginas que están bajo nuestro dominio.
Nuestro dominio principal recibe solicitudes de cuatro sistemas principales, cada uno con su propio soporte i18n y configurado en 3 idiomas: portugués, inglés y español. Estos son:
- nuestro blog;
- nuestros casos de éxito;
- nuestra documentación, y
- nuestras Landing Pages temporales creadas para nuestras campañas de marketing.
Aunque cada proyecto es independiente, todos ellos usan los mismos recursos.
¿Cuál es la relación entre los sitios web estáticos y la LCP?
La adopción de generadores de sitios estáticos (static site generators, SSG en el Front-End también ayuda a disminuir el tiempo de carga de una página. Los SSG permiten que una gran parte del contenido sea ensamblado durante el proceso de construcción, evitando un tiempo de procesamiento excesivo para todas y cada una de las solicitudes.
Para entender el porqué, primero debemos saber que es LCP (Largest Contentful Paint). Esta es una métrica que mide la percepción de la velocidad de carga del usuario en cada página. LCP calcula cuánto tiempo es requerido para mostrar la mayor parte del contenido (como imágenes y videos) en la pantalla desde que la página inicia la carga.
Un tiempo ideal de LCP puede ser el siguiente:
- Bueno: hasta 2.5 segundos;
- Necesita mejora: entre 2.5 y 4 segundos;
- Malo: más de 4 segundos.
Muchas veces, la percepción del usuario puede ser diferente a lo que nosotros medimos, por lo que es importante recordar que “la percepción del usuario es el rendimiento”, como fue mencionado por Guilherme Moser de Terra Networks.
Lo que hicimos
Usando las herramientas de Network and Coverage en Google Chrome Dev Tools, pudimos observar que algo estaba mal:
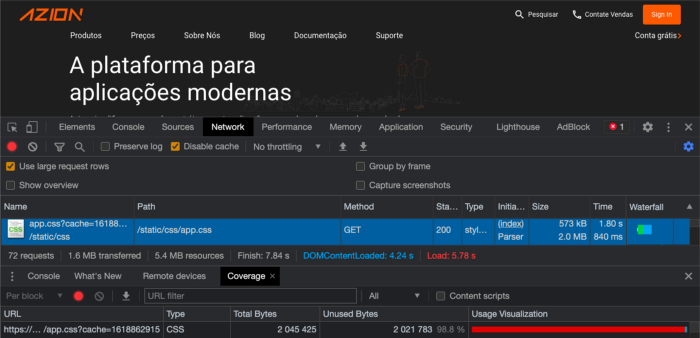
- en la franja azul, observamos que el CSS fue de 2.0 mb, y
- en la franja roja, observamos que el 98.8 % de su proceso fue empleado para tráfico innecesario.
Aunque hay capacidad de almacenamiento en caché a nivel del navegador, sería irresponsable confiar en este proceso. Además de disminuir la LCP, trae otros problemas como TTFB, TBT y TTI. Debido a este mal rendimiento, nos aseguramos de actualizar urgentemente nuestro sitio web basado en JAMStack. Así que nuestro trabajo fue dividir el CSS.
Dividir el CSS
Nuestra versión previa del sitio web tenía 3 páginas de CSS compilado para todas sus páginas, por lo que nuestro primer paso fue transformar todo lo que estaba en ./pages/_files.scss a ./pages/_page.scss. De esta forma, ni el destino ni el código necesitan ser alterados cuando son compilados con Jekyll. Así, todos los archivos que no tuvieran un _ (predeterminado en Sass), cuando se usaban como importación (import) en lugar de salida (output), generarían un archivo para cada salida compilada.
Lo que solía ser un archivo bundle.css inmenso de 200 mb, se convirtió en varios archivos más pequeños de aproximadamente 100 k, incluso antes de usar gzip.

¿Qué sucede con los archivos compilados? Examinamos cada archivo para verificar lo que era realmente necesario y llegamos a la siguiente compilación para todas las páginas:
El resultado final –y mucho más pequeño– fue:

Así una página con un número menor de componentes que tenía un tamaño de aproximadamente 90k después de ser compilada.
Integración con HTML
Para quienes usan las herramientas de SSG y están acostumbrados a configurar Front-Matters, estas herramientas tienen esta marca en la parte superior del archivo para mostrar cómo deben ser compiladas. Por este motivo, hicimos cambios pequeños en nuestras páginas.
Pasamos de una página con header HTML que contenía todo, como es mostrado en la siguiente imagen:

a:

Este nuevo estilo vendrá desde la configuración del Front-Matter, que es actualizada durante la construcción. Algo como:

Podemos observar que usamos la mayor parte de nuestros recursos existentes con alteraciones leves, lo que nos brindó enormes ventajas.
Nuestros resultados
Al final de este proceso, pudimos observar que alcanzamos una mejora del 70 % en:
- LCP: de 2.1 s a 1.3 s;
- First Byte: de 0.256 s a 0.18 s;
- Start render: de 1.9 s a 0.6 s;
- First Contentful Paint: de 1.8 s a 0.63 s, y
- Speed Index: de 2 s a 0.7 s.
De esta manera podemos apreciar que la importancia de la arquitectura JAMStack está cada vez más consolidada.





