Una región: global
- Ashburn
- Atlanta
- Chicago
- Dallas
- Denver
- Los Ángeles
- Miami
- Nueva York
- Phoenix
- San José
- Seattle
- Querétaro
Hiperconexión expresada en números
para alcanzar cualquier lugar de América y Europa
ASN conectados directamente a la red de Azion
de disponibilidad garantizada por SLA
edge locations en todo el mundo
La sólida estrategia de conectividad de Azion nos ayuda a brindar el mejor desempeño, disponibilidad y resiliencia a nuestros clientes.
Nuestra arquitectura altamente distribuida incluye edge nodes localizados estratégicamente en las redes de última milla de proveedores de servicios de Internet (ISP), conectividad a múltiples puntos de intercambio de Internet (IXP), peerings privados y públicos, y proveedores de tránsito de nivel 1 (tier 1) en todo el mundo.
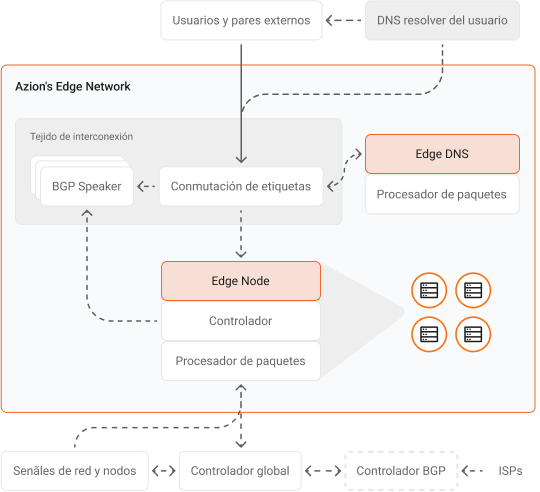
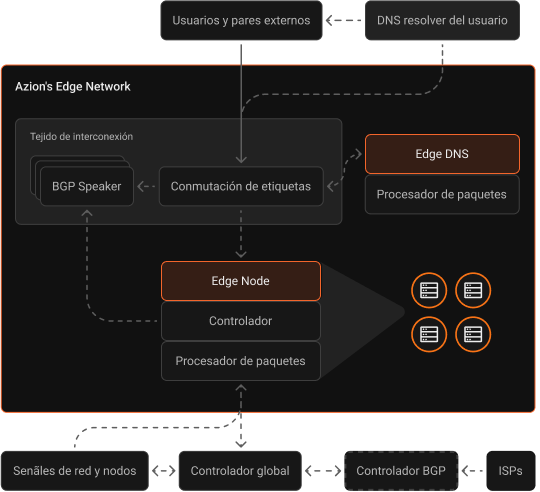
La red posee defensa DDoS en cada edge location y se conecta a varios centros de mitigación en todo el mundo, brindando confiabilidad total y sin afectar el desempeño.
La misión de crear una Internet más segura y fiable constituye para nosotros un valor fundamental. Por ello, para promoverla aún más también colaboramos, junto a otros actores del mercado, con la iniciativa MANRS (Mutually Agreed Norms for Routing Security) de la Internet Society.


Live Map de Azion
Descubre el comportamiento del e-commerce en tiempo real, los horarios con más tráfico y las regiones con un mayor número de ataques bloqueados.
Regístrate y recibe US$300 en créditos consumibles durante 12 meses.
Acceso a todos los productos
No necesitas tarjeta de crédito
Crédito disponible durante 12 meses