

Introdução: Desacoplando a AI dos Dados com o Model Context Protocol (MCP)
Para empresas modernas, a latência é uma barreira inflexível para a inteligência da AI. Sabemos bem que a latência de 200-500 ms das arquiteturas centralizadas não é apenas lenta, é um risco que drena receita e torna as estruturas vulneráveis a ataques, comprometendo os agentes de AI que prometeram transformar seu negócio. O que isso implica, no fim das contas, é que a AI “em tempo real” que prometeram é um mito na arquitetura de nuvem atual.
Os Modelos de Linguagem de Grande Escala (LLMs) possuem imenso potencial, mas seu estado padrão (alucinando com base em dados proprietários e em tempo real) compromete a receita e introduz riscos inaceitáveis para os negócios. Essa falha significa que os LLMs desconhecem as APIs internas, bancos de dados ativos e contextos operacionais de uma organização, obrigando desenvolvedores a construir soluções de integração muitas vezes frágeis, com alto acoplamento e código confuso, insustentável, justamente aquele que é caro e não escala.
Para enfrentar esse desafio, a Anthropic criou o Model Context Protocol (MCP), um padrão de código aberto projetado para funcionar como uma ponte universal e padronizada entre LLMs e contextos externos. O propósito do MCP é desacoplar a AI dos dados e ferramentas com os quais ela precisa interagir, permitindo que qualquer cliente compatível se conecte a capacidades de AI de terceiros sem integrações personalizadas e rígidas. Em essência, o MCP funciona como uma “porta USB” para AI, fornecendo uma interface padrão na qual diversos componentes (como APIs internas, feeds de dados ao vivo ou funções especializadas) podem ser conectados para ampliar o poder do modelo de linguagem.
Os próximos parágrafos desse texto demonstram que implantar servidores MCP em uma plataforma descentralizada e serverless como a Azion oferece a arquitetura ideal para alcançar a baixa latência, alta escalabilidade e segurança robusta necessárias para aplicações de AI em nível de produção. Ao mover o ponto de conexão entre o LLM (generalista) e os contextos internos (especialistas) para a borda da rede, organizações podem construir sistemas movidos a AI rápidos, seguros e confiáveis.
Tenha em mente que permanecer na nuvem, ou seja, construir outra integração personalizada e fortemente acoplada para seu LLM, não é inovação, é dívida técnica disfarçada. Executar o MCP em uma região centralizada é como colocar um motor de Ferrari em um carrinho de golfe. É o equivalente ao rack de servidores local da era da AI.
Agora vamos explorar os componentes fundamentais do protocolo que tornam isso possível.
Os 3 Pilares do MCP: Como o Protocolo dá Visão, Ação e Memória à sua AI
Entender o design estratégico da arquitetura cliente-servidor do MCP é fundamental para apreciar suas potencialidades. Essa separação de responsabilidades permite que sistemas de AI sejam mais modulares, escaláveis e seguros.
A aplicação que contém o LLM (o host) é diferente do servidor que fornece acesso a sistemas externos, o que cria uma divisão clara para gerenciar permissões e fluxo de dados. Em suma, a arquitetura é composta por três componentes-chave:
- Host: Esta é a aplicação voltada para o usuário (por exemplo, um chatbot, um IDE de código como o Cursor ou uma ferramenta de software empresarial) que contém o LLM e orquestra a interação.
- Cliente: A aplicação host gerencia um ou mais clientes. Cada cliente mantém uma conexão independente e isolada com um único servidor MCP, garantindo que os contextos não se misturem. Mais do que manter conexões, o cliente atua como um “guardião”, impedindo que, por exemplo, dados de RH se misturem com conteúdos de marketing.
- Servidor: O servidor MCP é um programa independente que atua como um conector seguro. Ele fornece contexto especializado e capacidades para a aplicação de AI ao expor uma interface padronizada para interagir com sistemas externos, como bancos de dados, APIs e ferramentas empresariais proprietárias.
Ou seja, pare de construir bots “onipotentes / god mode”, construa servidores MCP especializados que fazem uma coisa com perfeição.
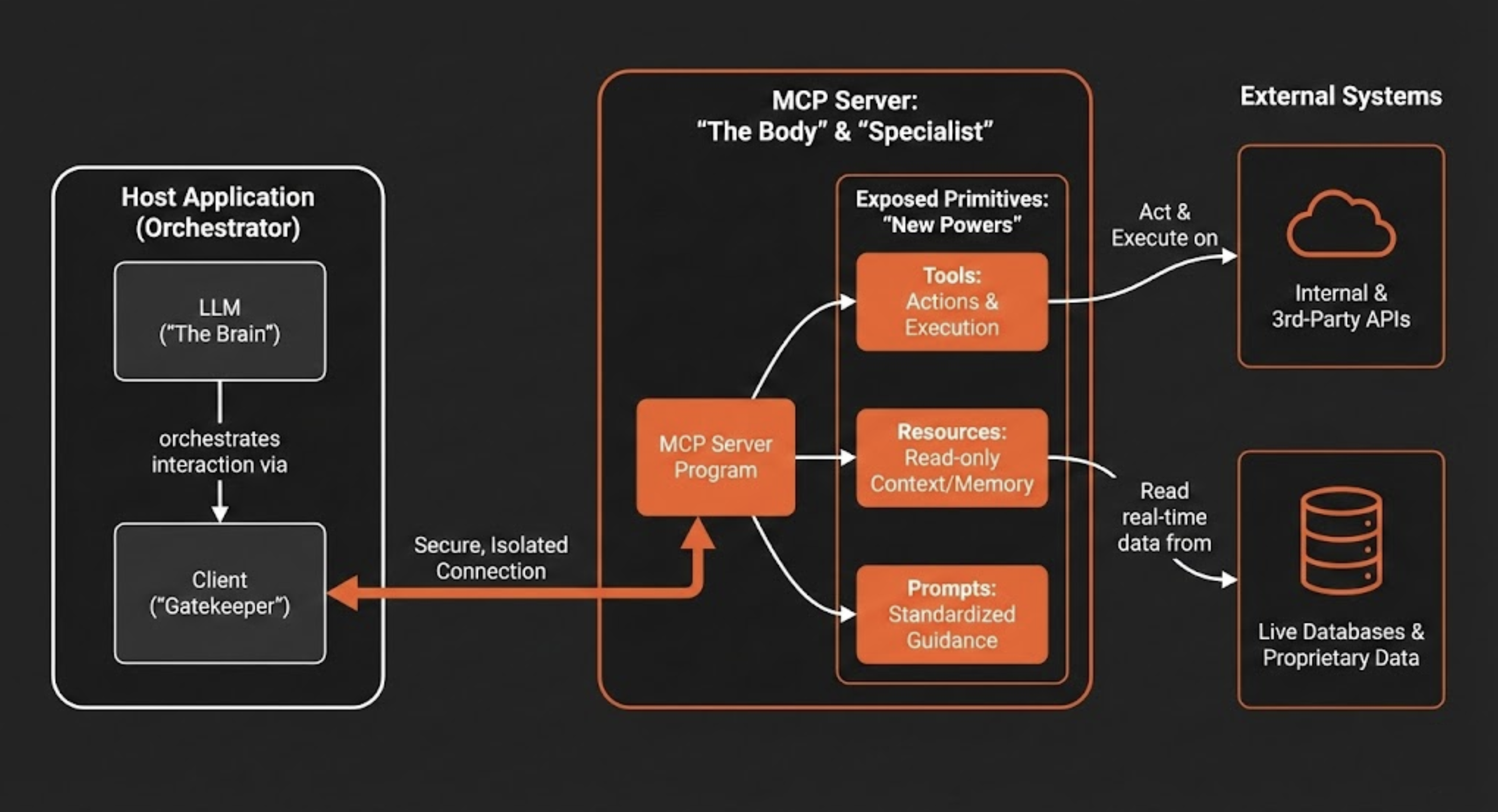
Esta arquitetura permite que um LLM acesse e utilize capacidades externas por meio de três primitivas fundamentais que um servidor MCP expõe. Essas primitivas dão à AI novos “poderes” para ver, agir e se comunicar de maneira estruturada.
Comparativamente, o host atua como o Cérebro (Inteligência), o Servidor é o Corpo (Capacidades), e as Conexões atuam como o Sistema Nervoso. Em outras palavras, um LLM sem um servidor MCP é como um cérebro em uma jarra. É inteligente, mas totalmente impotente para afetar o mundo físico.
1. Ferramentas → A diferença entre falar e fazer
Ferramentas são funções executáveis que permitem a um LLM realizar ações. Uma ferramenta pode ir de uma simples calculadora a um fluxo de trabalho complexo que invoca APIs internas ou de terceiros. Quando um LLM determina que uma ação é necessária para atender à solicitação de um usuário, ele pode chamar a ferramenta apropriada exposta pelo servidor MCP, como, por exemplo, deploy\_azion\_static\_site para orquestrar uma implantação, create\_graphql\_query para buscar dados analíticos ou create\_rules\_engine para configurar o comportamento da aplicação.
2. Recursos → A base para evitar alucinações
Recursos são fontes de dados somente leitura que fornecem contexto adicional ao LLM, funcionando como uma memória estendida. Sua função é oferecer a base factual necessária para reduzir “alucinações” do modelo. Ao garantir que as respostas se apoiem em dados verificáveis, os recursos aumentam a confiabilidade da AI. Exemplos incluem o conteúdo de um arquivo, o esquema de um banco de dados, o status em tempo real de uma API ou o estado atual de um pull request.
3. Prompts → Codificando o conhecimento institucional
Prompts são templates, modelos pré-definidos e compartilhados que guiam a interação da AI com ferramentas e recursos específicos. Eles garantem que as interações sejam consistentes, de alta qualidade e alinhadas com os padrões organizacionais. Por exemplo, equipes de marketing poderiam usar prompts padronizados para gerar conteúdos de campanha, enquanto isso, equipes de design poderiam usar prompts pré-configurados para criar imagens alinhadas à marca, isso garante que todos usem as mesmas instruções testadas e otimizadas.
Ao compreender esses componentes centrais e as primitivas, torna-se claro como o MCP fornece uma estrutura resiliente para estender a AI. A próxima consideração crítica desse texto é onde executar essa arquitetura para maximizar sua eficácia.
A Mentira da AI “Tempo Real” (e Como Consertar Isso na Prática)
O desempenho e a confiabilidade de uma aplicação de AI dependem criticamente da infraestrutura subjacente. Embora as arquiteturas de nuvem centralizadas tradicionais tenham sido o padrão por anos, elas introduzem um gargalo significativo para AI em tempo real: latência de rede. O tempo de ida e volta necessário para os dados viajarem do dispositivo de um usuário até um data center de nuvem distante e voltarem compromete a natureza interativa e responsiva que define uma experiência de AI de alta qualidade. Implantar servidores MCP na plataforma da Azion soluciona diretamente esse desafio, criando o ambiente ideal para AI de alto desempenho.
Latência Mínima
Ao executar tanto a lógica do servidor MCP quanto os modelos de AI diretamente em edge nodes geograficamente próximos ao usuário final, a Azion reduz drasticamente o tempo de ida e volta na rede. Enquanto endpoints de inferência de AI hospedados na nuvem atingem uma faixa de latência mediana de 200–500ms (uma eternidade para aplicações em tempo real), uma arquitetura que prioriza a borda e executa o stack de AI completo localmente permite tempos de resposta abaixo de 100ms, o que é essencial para experiências interativas. Casos de uso como personalização em tempo real, precificação dinâmica e detecção instantânea de fraudes, nos quais decisões movidas pela AI devem ser tomadas em um piscar de olhos, tornam-se práticas quando tanto a camada de orquestração (MCP) quanto a camada de inteligência (AI Inference) operam na borda.
Escalabilidade Elástica e Alta Disponibilidade
Os workloads de AI são frequentemente variáveis e imprevisíveis. As Functions da Azion, juntamente com AI Inference, são projetadas para escalar automaticamente e globalmente em resposta à demanda, garantindo que o servidor MCP possa lidar com picos repentinos de tráfego sem intervenção manual ou perda de desempenho. Esta arquitetura distribuída também fornece alta disponibilidade inerente; se uma localização de borda apresenta um problema, o tráfego é redirecionado automaticamente para o node saudável mais próximo, mantendo a aplicação operacional.
Segurança Aprimorada e Soberania de Dados
Processar dados sensíveis na região geográfica do usuário, é uma estratégia poderosa para compliance e segurança. Isso ajuda organizações a aderir a regulamentações de residência de dados como GDPR e LGPD ao minimizar a transmissão de dados pessoais além-fronteiras. Além disso, ao processar solicitações localmente, esta arquitetura reduz a exposição ao minimizar a necessidade de transmitir dados por redes públicas inseguras, diminuindo a superfície geral de ataque.
Custo-Efetividade
As Functions da Azion operam em um modelo de “escalar até zero”, uma marca registrada da computação sem servidor. Isso significa que você paga apenas pelos recursos computacionais quando seu servidor MCP está processando ativamente uma solicitação. Para aplicações com tráfego variável ou intermitente, este modelo é muito mais econômico do que manter e pagar por servidores centralizados ociosos, garantindo que os custos de infraestrutura se alinhem diretamente com o uso.
Essas vantagens arquiteturais estabelecem o “porquê” de executar o MCP na borda. A próxima seção detalhará o “como”, fornecendo um guia prático de implementação.
Tutorial Prático: Implante um Servidor MCP de Alta Performance em Menos de 5 Minutos
Esta seção fornece um guia prático, passo a passo, para desenvolvedores criarem e implantarem um servidor MCP funcional usando Azion Functions. O processo foi simplificado para permitir implantação rápida, permitindo que você conecte sua AI a ferramentas e dados externos em minutos.
Criando a Function
A configuração inicial é concluída por meio do Console Azion com alguns passos simples:
- Acesse o Console Azion.
- No menu superior esquerdo, navegue até a seção Functions.
- Clique em + Function.
- Atribua um nome descritivo à sua função.
- Selecione o ambiente de execução Application.
- Cole o código na aba Code.
Uma vez criada a função, você pode implementar seu servidor MCP usando uma das duas abordagens principais a seguir, cada uma adequada para diferentes níveis de controle e complexidade.
Opção 1: High-Level McpServer
Esta abordagem é ideal para desenvolvimento rápido e simplicidade. A classe McpServer abstrai grande parte do código padrão, permitindo que você registre rapidamente suas ferramentas, recursos e prompts com chamadas simples.
import { Hono } from 'hono'import { StreamableHTTPServerTransport } from '@modelcontextprotocol/sdk/server/streamableHttp.js'import { toFetchResponse, toReqRes } from 'fetch-to-node'
const app = new Hono()const server = new McpServer({ name: "azion-mcp-server", version: "1.0.0"});
server.registerTool("add", { title: "Addition Tool", description: "Adds two numbers", inputSchema: { a: z.number(), b: z.number() }}, async ({ a, b }) => ({ content: [{ type: "text", text: String(a + b) }]}));
server.registerResource( "greeting", new ResourceTemplate("greeting://{name}", { list: undefined }), { title: "Greeting Resource", description: "Dynamic greeting generator" }, async (uri, { name }) => ({ contents: [{ uri: uri.href, text: `Hello, ${name}!` }] }));
app.post('/mcp', async (c: Context) => { try { const { req, res } = toReqRes(c.req.raw); const transport: StreamableHTTPServerTransport = new StreamableHTTPServerTransport({ sessionIdGenerator: undefined }); await server.connect(transport); const body = await c.req.json(); await transport.handleRequest(req, res, body); res.on('close', () => { console.log('Connection closed.'); transport.close(); server.close(); }); return toFetchResponse(res); } catch (error) { console.error('Error handling MCP request:', error); const { req, res } = toReqRes(c.req.raw); if (!res.headersSent) { res.writeHead(500).end(JSON.stringify({ jsonrpc: '2.0', error: { code: -32603, message: 'Internal server error' }, id: null, })); } }});
export default appOpção 2: Low-Level Server
Para desenvolvedores que requerem controle mais granular, a classe Server de baixo nível é a melhor opção. Esta abordagem é necessária para implementar lógica personalizada complexa, integrar com sistemas legados que exigem transformações de dados específicas, ou ajustar com precisão caminhos de solicitação/resposta críticos para desempenho que a abstração McpServer de alto nível pode não contemplar. Ela requer que você implemente os manipuladores de solicitação para cada operação MCP diretamente, dando a ele autoridade completa sobre como o servidor responde.
import { Hono } from 'hono';import { StreamableHTTPServerTransport } from '@modelcontextprotocol/sdk/server/streamableHttp.js';import { Server } from '@modelcontextprotocol/sdk/server/index.js';import { CallToolRequestSchema, ListToolsRequestSchema, ErrorCode, McpError,} from '@modelcontextprotocol/sdk/types.js';import { toFetchResponse, toReqRes } from 'fetch-to-node';
// 1. Defina suas ferramentas manualmente (ou busque-as do seu banco de dados)const TOOLS = [ { name: "calculate_sum", description: "Soma dois números", inputSchema: { type: "object", properties: { a: { type: "number" }, b: { type: "number" } }, required: ["a", "b"] } }];
// 2. Inicialize a instância do Servidorconst server = new Server({ name: 'azion-low-level-mcp', version: '1.0.0',}, { capabilities: { tools: {}, // Anuncia que este servidor suporta ferramentas },});
// 3. Registre o manipulador para listar ferramentasserver.setRequestHandler(ListToolsRequestSchema, async () => { return { tools: TOOLS, };});
// 4. Registre o manipulador para chamar ferramentasserver.setRequestHandler(CallToolRequestSchema, async (request) => { const { name, arguments: args } = request.params;
if (name === "calculate_sum") { // A validação de argumentos em tempo de execução é crucial em implementações de baixo nível if (!args || typeof args.a !== 'number' || typeof args.b !== 'number') { throw new McpError(ErrorCode.InvalidParams, "Argumentos inválidos para soma"); }
const result = args.a + args.b;
return { content: [{ type: "text", text: String(result) }] }; }
throw new McpError(ErrorCode.MethodNotFound, `Ferramenta não encontrada: ${name}`);});
const app = new Hono();
// 5. Conecte o adaptador HTTP Hono ao transporte MCPapp.post('/mcp', async (c) => { try { const { req, res } = toReqRes(c.req.raw);
// Crie o transporte especializado para streaming sobre HTTP const transport = new StreamableHTTPServerTransport({ sessionIdGenerator: undefined, // padrão });
await server.connect(transport);
// Processe a mensagem JSON-RPC await transport.handleRequest(req, res, await c.req.json());
// Limpe quando a conexão fechar res.on('close', () => { transport.close(); server.close(); });
return toFetchResponse(res); } catch (error) { console.error('Erro ao processar requisição MCP:', error); return c.json({ jsonrpc: '2.0', error: { code: -32603, message: 'Erro interno do servidor' }, id: null }, 500); }});
export default app;Para auxiliar desenvolvedores usando a abordagem Server de baixo nível, as tabelas seguintes fornecem uma referência rápida para os esquemas de handlers de request disponíveis.
Tabela 1: Schemas para Listar Propriedades
Schema | Descrição |
| Lista ferramentas disponíveis. |
| Lista recursos disponíveis. |
| Lista prompts disponíveis. |
Tabela 2: Schemas para Invocar Propriedades
Schema | Descrição |
| Invoca uma ferramenta específica. |
| Lê dados de um recurso. |
| Recupera um prompt específico. |
Com o servidor funcionando e implantado, o próximo imperativo, portanto, é garantir que ele esteja fortificado contra ameaças potenciais.
Segurança de AI: Por que seu Agente precisa de uma Badge, não da senha do Admin
Implantar um servidor MCP requer uma postura de segurança robusta. Como agentes de AI podem executar ações em nome de um usuário, eles criam uma nova superfície de ataque complexa com que modelos de segurança tradicionais não estão preparados para lidar. A abordagem viável é o modelo Zero Trust, “nunca confie, sempre verifique”. Cada solicitação deve ser autenticada e autorizada, independentemente da origem, garantindo proteção contínua.
Os principais riscos de segurança associados a servidores MCP incluem:
- Injeção de Prompt: Um ataque em que um ator malicioso incorpora instruções ocultas dentro de um prompt de usuário aparentemente inofensivo. Como os LLMs frequentemente não diferenciam entre instruções do sistema e input do usuário, esses comandos ocultos podem enganar o modelo para realizar ações não autorizadas, como extrair arquivos sensíveis ou enviar e-mails maliciosos.
- O Problema do “Confused Deputy”: Esta vulnerabilidade surge quando um agente de AI com privilégios elevados é enganado por um usuário com privilégios menores para usar indevidamente sua autoridade. Por exemplo, um usuário de baixo privilégio poderia elaborar uma solicitação que faz com que uma IA de alto privilégio acesse ou modifique recursos que o próprio usuário não deveria ser capaz de alcançar.
- Execução Não-Autorizada de Comandos: Se um servidor MCP não é executado em um ambiente isolado, um atacante poderia explorar uma vulnerabilidade para executar código arbitrário no sistema host. Isso representa uma falha de segurança crítica que poderia levar a um comprometimento completo do sistema.
Para se defender contra essas ameaças, uma estratégia de segurança de zero trust em múltiplas camadas é essencial. As seguintes táticas de mitigação formam a base de uma implantação MCP segura:
- Isolar Ambientes de Execução: Cada servidor MCP deve ser tratado como código não confiável e implantado em um ambiente isolado (sandbox). Plataformas serverless seguras como a Azion fornecem esse isolamento por padrão, impedindo que um servidor comprometido acesse o sistema host subjacente ou outros serviços.
- Implementar Autenticação e Autorização Robustas: O acesso a ferramentas, recursos e prompts deve ser estritamente controlado. Implementar padrões modernos como OAuth para autenticação e Controle de Acesso Baseado em Funções (RBAC) é crítico. Isso garante que apenas usuários e sistemas autorizados possam invocar ferramentas específicas ou acessar dados sensíveis, aplicando o princípio do menor privilégio.
- Aproveitar Inteligência de Ameaças Integrada: Uma plataforma robusta deve fornecer detecção de ameaças integrada e em tempo real. O Web Application Firewall (WAF) da Azion atua como um perímetro defensivo crucial, inspecionando o tráfego e bloqueando payloads maliciosos (OWASP TOP10) antes que possam comprometer o servidor MCP. As Functions também podem ser adaptadas para funcionar como uma barreira programável e extensível para suas aplicações para promover Lógica de Segurança Personalizada e Análise Preditiva, por exemplo.
Uma postura de segurança robusta protege a integridade de seus sistemas de AI. O próximo passo é garantir que eles também estejam com desempenho ideal.
As 4 Métricas que Realmente Importam para um Agente de AI
Métricas tradicionais de desempenho de servidor, como utilização de CPU ou tempo de resposta básico, são insuficientes para avaliar a saúde e o sucesso de um sistema de IA. Para servidores MCP, o sucesso não é apenas sobre quão rápido um servidor responde; é sobre a qualidade, velocidade e confiabilidade de toda a interação do usuário de ponta a ponta. Portanto, um conjunto mais abrangente de métricas é necessário para realmente compreender o desempenho.
Os indicadores-chave de desempenho (KPIs) para uma implementação saudável de servidor MCP incluem:
-
Tempo até o Primeiro Token / Time to First Token (TTFT)
Isso mede o tempo desde quando um usuário envia uma solicitação até quando a primeira parte da resposta gerada pela IA aparece. TTFT é uma métrica crítica para a responsividade percebida pelo usuário, pois um valor baixo faz a aplicação parecer rápida e interativa, mesmo que a resposta completa demore mais para ser gerada.
-
Throughput
Definido como o número de solicitações ou tokens que o sistema pode processar por unidade de tempo, o throughput é uma medida da capacidade do servidor. Alta taxa de transferência garante que a aplicação possa lidar com cargas de pico e escalar efetivamente sem degradar o desempenho para usuários individuais.
-
Fundamentação (“Groundedness”)
Esta é uma métrica de qualidade que avalia quão bem a resposta do modelo é apoiada pelo contexto fornecido pelo servidor MCP. Alta fundamentação indica que a IA está confiando em dados factuais de suas ferramentas e recursos, o que é o oposto direto de um modelo “alucinando” ou inventando informações.
-
Taxa de Conclusão de Tarefas
Para agentes de IA projetados para realizar tarefas complexas e de múltiplas etapas, esta métrica mede a porcentagem dessas tarefas que são concluídas com sucesso. É um indicador direto da confiabilidade e utilidade prática do agente.
A tabela seguinte resume as métricas-chave, suas importâncias e alvos de desempenho típicos para sistemas de IA implantados em uma plataforma de alto desempenho.
Métrica | Por que importa | Alvo Típico |
Latência p95 | Mantém lentidões de pico sob controle | < 150 ms ponta a ponta |
Tempo até o Primeiro Token (TTFB) | Melhora o desempenho percebido | < 400 ms |
Métricas de Throughput | Garante capacidade sob carga | Alvo de RPS Sustentado |
Precisão de Busca Semântica | Protege a qualidade da resposta | 85–95% por intenção |
Para rastrear efetivamente essas métricas é essencial contar com uma plataforma de observabilidade robusta. Usar padrões abertos como OpenTelemetry permite que desenvolvedores instrumentem cada componente do sistema, desde a função até as chamadas de banco de dados, e agreguem dados de desempenho. Ferramentas integradas da plataforma como Real-Time Metrics e Data Stream da Azion fornecem um painel unificado para esses dados, criando uma única fonte de verdade que é inestimável para solucionar gargalos e garantir uma experiência de usuário de alta qualidade.
Monitorar o desempenho garante excelência operacional; o passo final é ver os resultados em produção.
Conclusão: O Futuro da IA Conectada é Distribuído (não é um Diferencial, é uma Obrigação)
O Model Context Protocol (MCP) emergiu como um padrão aberto essencial, fornecendo uma estrutura segura e escalável para conectar Modelos de Linguagem de Grande Escala aos dados ao vivo e ferramentas interativas de que precisam para serem verdadeiramente eficazes. Ao criar uma interface universal, o MCP elimina a necessidade de integrações personalizadas e frágeis e desbloqueia todo o potencial dos agentes de IA para atuarem como parceiros inteligentes em fluxos de trabalho complexos.
Como este texto demonstrou, o poder do protocolo só é totalmente realizado quando implantado em uma arquitetura projetada para as demandas da IA moderna. Uma plataforma como a Azion representa a melhor escolha arquitetural, abordando diretamente os requisitos críticos de tempo de ida e volta reduzido, escalabilidade elástica e segurança robusta. Ela permite as interações abaixo de 100ms que definem aplicações em tempo real, garante disponibilidade global e compliance com regulamentações de soberania de dados, e fornece um modelo operacional econômico e de pagamento conforme o uso.
A combinação de MCP e computação de borda sem servidor é mais do que apenas uma solução técnica; é um habilitador estratégico. Significa que a lacuna entre os líderes na borda e aqueles que confiam apenas na nuvem está se ampliando a cada hora. Você pode construir a infraestrutura do futuro hoje ou pagar a dívida técnica do passado pelos próximos 10 anos.
Comece gratuitamente hoje ou nos envie um e-mail para sales@azion.com.
Perguntas Frequentes: Model Context Protocol
P: O que é Model Context Protocol (MCP)?
R: MCP é um padrão de código aberto da Anthropic que conecta LLMs a fontes de dados externas e ferramentas através de uma interface universal, eliminando integrações personalizadas.
P: Por que implantar servidores MCP no edge versus na nuvem?
R: A implantação na borda reduz a latência de 200-500ms para <100ms, fornece escalabilidade global automática, garante conformidade com GDPR e reduz custos em 70% com cobrança por uso.
P: Qual é a diferença entre ferramentas e recursos do MCP?
R: Ferramentas são funções executáveis (ações que a IA pode realizar). Recursos são fontes de dados somente de leitura (contexto que previne alucinações).
P: O MCP é seguro para implantações de AI em produção?
R: Sim, com implementação adequada: execução em sandbox, autenticação OAuth, autorização RBAC, proteção WAF na borda e registro de auditoria abrangente.
P: Quanto tempo leva a implantação do servidor MCP?
R: Implantação inicial: 5 minutos. Pronto para produção com segurança: 2-4 semanas seguindo a lista de verificação de implementação.
P: Quais são os alvos típicos de desempenho do MCP?
R: TTFT <400ms, latência p95 <150ms, fundamentação 85-95%, taxa de transferência sustentada correspondendo aos seus padrões de tráfego.
P: O MCP pode funcionar com qualquer LLM?
R: MCP é um padrão aberto. Qualquer cliente compatível pode se conectar a servidores MCP, embora a qualidade da implementação varie por provedor.
P: Qual é o ROI da implantação MCP na borda?
R: Melhoria de latência de 3-5x, ganhos de taxa de conversão de 23% (e-commerce), redução de 70% nos custos de infraestrutura e novas capacidades de IA em tempo real anteriormente impossíveis.




