Construir
AI Inference
Implante e execute inferência de AI serverless para LLMs, VLMs, embeddings e modelos multimodais com uma API compatível com OpenAI. Entregue experiências de usuário mais rápidas em infraestrutura distribuída, com escalonamento automático e sem clusters de GPU para gerenciar.
mais rápido que clouds tradicionais
tokens por segundo de velocidade de saída
menor latência
Inferência de baixa latência para experiências de usuário em tempo real
Mantenha time-to-first-token e latência end-to-end baixos com execução distribuída. Construído para aplicações interativas, respostas em streaming e tomada de decisão em tempo real.
Escalonamento serverless sem operações de GPU
Lide com demanda variável sem provisionar clusters de GPU. Escale automaticamente da primeira requisição até o pico de carga, mantendo custos alinhados com o uso.
Confiável por design para workloads de produção
Execute inferência mission-critical com arquitetura distribuída e failover automático, projetado para manter recursos de AI disponíveis quando o tráfego aumenta ou regiões falham.

"Com a Azion, conseguimos escalar nossos modelos proprietários de AI sem precisarmos nos preocupar com a infraestrutura. Essas soluções inspecionam milhões de websites diariamente, detectando e neutralizando ameaças com rapidez e precisão, realizando o takedown mais rápido do mercado."
Fabio Ramos
CEO
Construa, personalize e sirva modelos de AI em produção
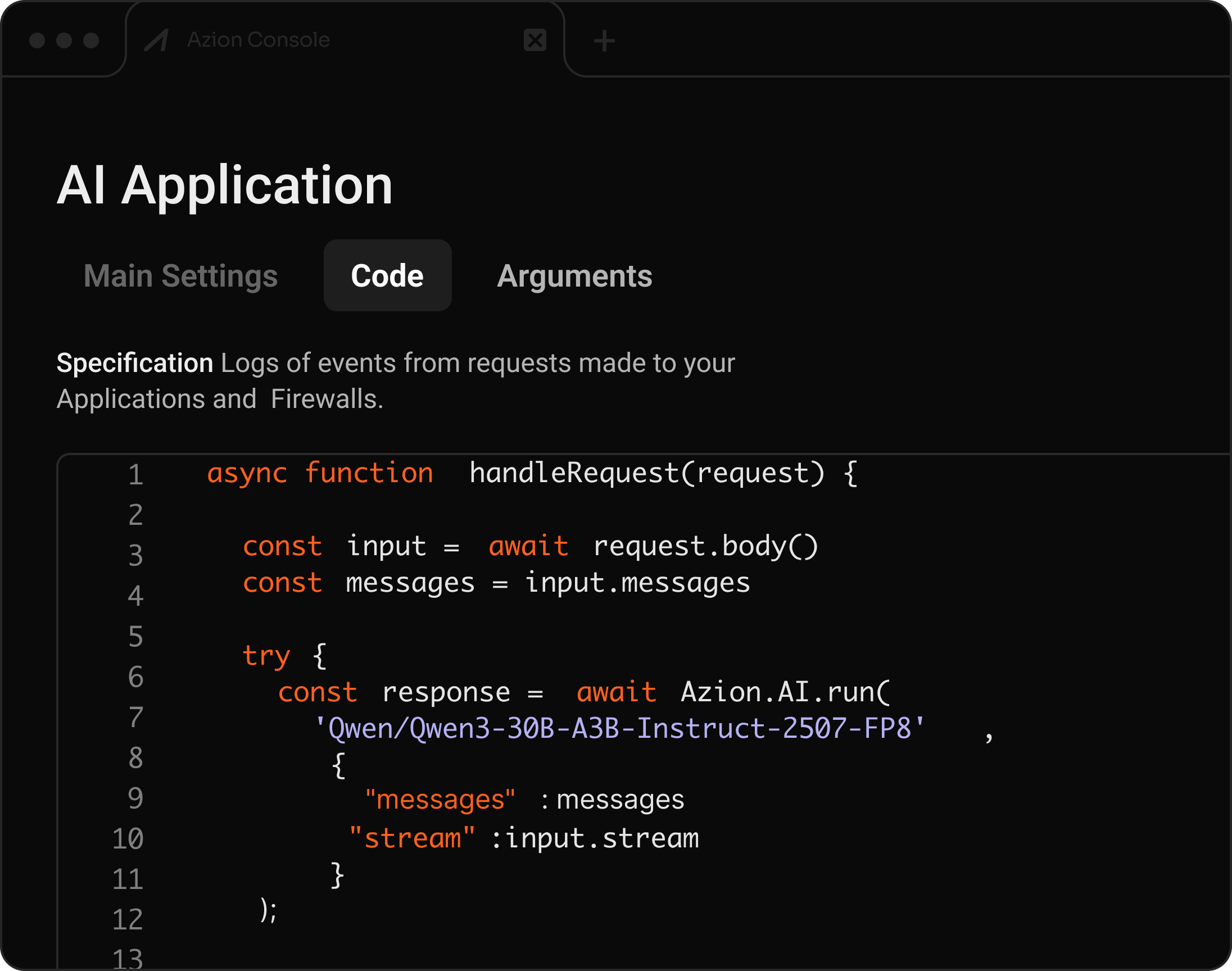
API compatível com OpenAI para inferência de AI serverless
Implemente e rode modelos LLM, VLM, Embeddings, Audio to Text, Text to Image, Tool Calling, LoRA, Rerank e Coding LLM — tudo integrado a aplicações distribuídas.
LLMs & VLMsIntegração com FunctionsCompatível com OpenAIAuto-scaling
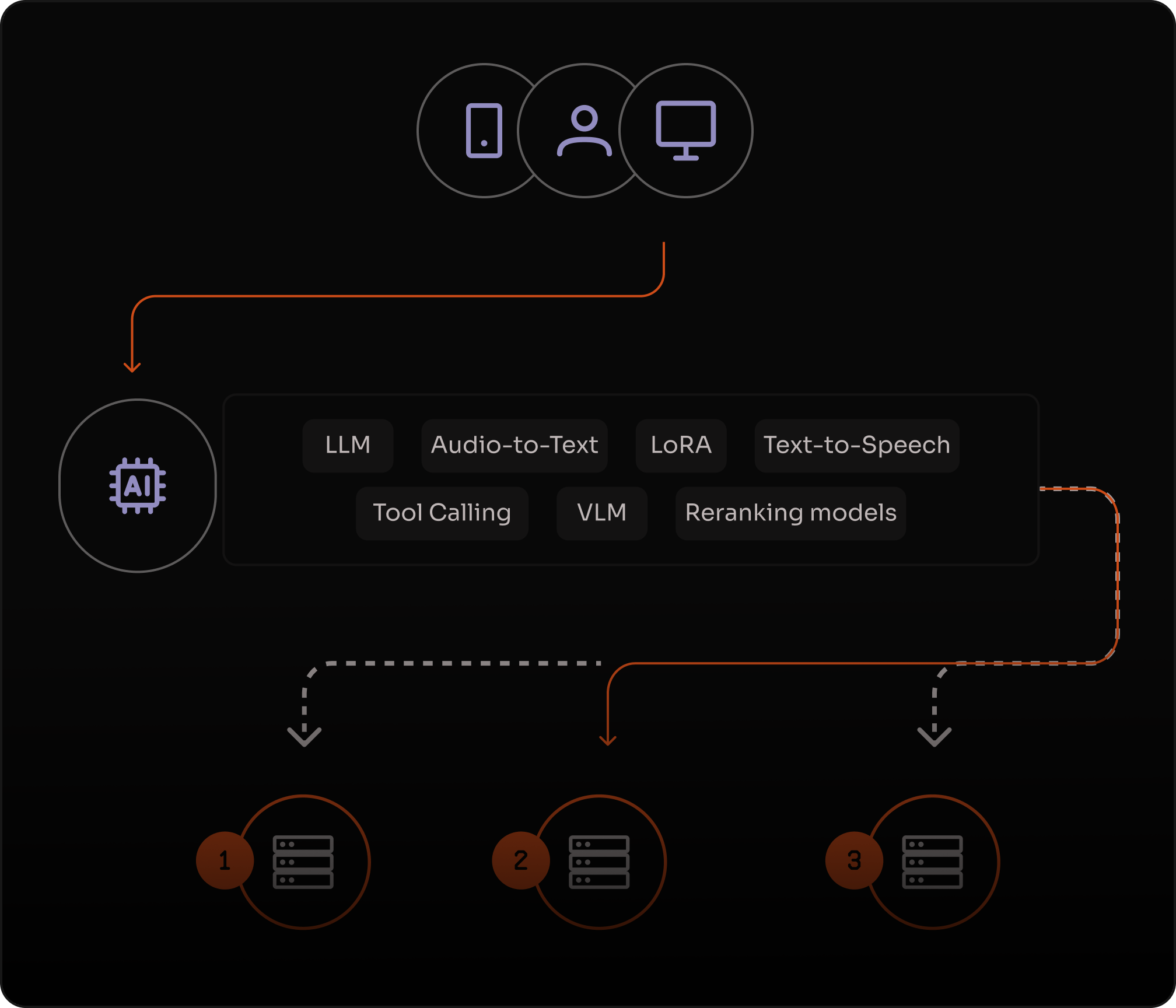
Fine-tune com LoRA para desempenho específico de domínio
Ajuste modelos de IA com Low-Rank Adaptation (LoRA) para personalizar inferências, otimizar desempenho e reduzir custos de treinamento.
Adapte parâmetros de forma eficiente e resolva problemas complexos com menor uso de recursos.
Fine-tuning LoRAPersonalização de domínioSem retreinamento completoMenor custo de compute
O que você pode construir com AI Inference
Perguntas Frequentes
O que é Azion AI Inference?
Azion AI Inference é uma plataforma serverless para implantar e executar modelos de AI globalmente. Recursos principais incluem: API compatível com OpenAI para migração fácil, suporte a LLMs, VLMs, embeddings e reranking, escalonamento automático sem gerenciamento de GPU, e execução distribuída de baixa latência. Crie endpoints de produção e integre-os em Applications e Functions.
Quais modelos posso executar?
Você pode escolher de um catálogo de modelos open-source disponíveis no AI Inference. O catálogo inclui diferentes tipos de modelos para workloads comuns (geração de texto e código, vision-language, embeddings e reranking) e evolui conforme novos modelos ficam disponíveis.
É compatível com a API da OpenAI?
Sim. AI Inference suporta um formato de API compatível com OpenAI, então você pode manter seus SDKs de cliente e padrões de integração e migrar atualizando a URL base e credenciais. Veja a documentação do produto: https://www.azion.com/pt-br/documentacao/produtos/ai/ai-inference/
Posso fazer fine-tuning de modelos?
Sim. AI Inference suporta customização de modelos com Low-Rank Adaptation (LoRA), então você pode especializar modelos open-source para seu domínio sem retreinamento completo. Guia inicial: https://www.azion.com/pt-br/documentacao/produtos/guias/ai-inference-starter-kit/
Como construo RAG e busca semântica?
Use AI Inference com SQL Database Vector Search para armazenar embeddings e recuperar contexto relevante para Retrieval-Augmented Generation (RAG). Isso permite padrões de busca semântica e busca híbrida sem infraestrutura adicional.
Posso construir AI agents e workflows com tool-calling?
Sim. AI Inference pode ser usado para alimentar padrões de agentes (por exemplo, ReAct) e workflows com tool-calling quando combinado com Applications, Functions e ferramentas externas. A Azion também fornece templates e guias para agentes baseados em LangChain/LangGraph.
Como faço deploy de AI inference na minha aplicação?
Crie um endpoint de AI Inference e integre-o ao seu fluxo de requisições usando Applications e Functions. Isso permite adicionar capacidades de AI a APIs existentes e experiências de usuário com execução distribuída e escalonamento gerenciado.