
No artigo anterior, falamos como foi a introdução do JAMStack no site da Azion. Aqui, falaremos sobre os resultados das small actions na otimização da quantidade de recursos usados, resultando na melhora expressiva de tempo de carregamento das mais de 900 páginas guardadas sob nosso domínio.
Nosso domínio principal recebe pedidos de quatro sistemas principais, cada um com seu próprio suporte i18n configurado para três idiomas: português, inglês e espanhol. São eles:
- o blog;
- os casos de sucesso;
- nossa documentação;
- as Landing Pages temporárias criadas para o marketing dos nossos produtos.
Apesar de cada um ser um projeto separado, todos usam os mesmos recursos.
Qual é a relação entre sites estáticos e o LCP?
Adotar SSG (Static Site Generators, ou Geradores de Páginas Estáticas em português) no front end também ajuda a diminuir o tempo de carregamento das páginas. Os SSGs permitem montar grande parte do conteúdo em tempo de build, evitando o tempo de processamento de cada requisição.
Para entender por que adotar, primeiro é necessário saber o que é o LCP (Largest Contentful Paint), uma métrica para mensurar a percepção do load speed de cada página por parte do usuário. O LCP calcula quanto tempo leva para mostrar o maior conteúdo (como imagens ou vídeos) na tela desde que a página começou a ser carregada.
O tempo ideal de LCP é o seguinte:
- Bom: até 2,5 segundos;
- Precisa melhorar: entre 2,5 e 4 segundos;
- Ruim: acima de 4 segundos.
Muitas vezes, no entanto, a percepção do usuário pode ser diferente do que realmente mensuramos, então é importante lembrar que “a percepção de usuário é performance”, como foi dito por Guilherme Moser da Terra Networks.
O que fizemos?
De acordo com as ferramentas de Network e Coverage do Google Chrome Dev Tools, podíamos ver que havia algo errado:
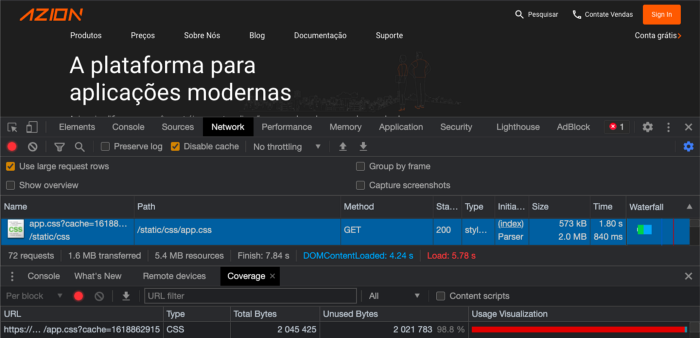
- Na faixa azul, vemos que o CSS é de 2.0mb;
- Já na faixa vermelha, vemos que 98,8% do processamento de CSS é usado para tráfego desnecessário.
Mesmo com a possibilidade de fazer cache no browser, seria uma irresponsabilidade contar com esse processo. Além de prejudicar o LCP, isso acarretaria outros problemas como TTFB, TBT e TTI.
Com esse péssimo desempenho, tivemos certeza de que precisávamos urgentemente atualizar a estrutura do nosso site baseado em JAMStack. A partir disso, nosso trabalho foi quebrar o CSS.
Quebrando o CSS
A primeira versão do nosso site contava com um compilado de 3 páginas de CSS para todas as páginas.
O primeiro passo foi transformar o que estava em ./pages/_file.scss para ./pages/_page.scss. Dessa forma, nem o destino nem o código precisam ser alterados quando são compilados pelo Jekyll. Assim, cada arquivo que não tiver _ (o que é default no SaaS) no momento em que for usar como import, em vez de output geraria um arquivo por output quando for compilado.
O que era um bundle.css imenso de 200mb passou a ser vários arquivos menores de mais ou menos 100k, isso sem contar o gzip.

E os arquivos compartilhados? Testamos arquivo por arquivo para ver o que realmente era necessário ou não, e com isso chegamos ao seguinte compilado para todas as páginas:
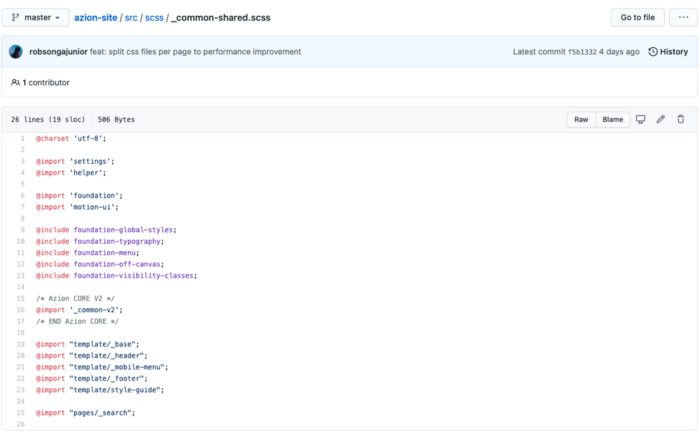
O resultado final – e bem menor do que o original – ficaria assim:
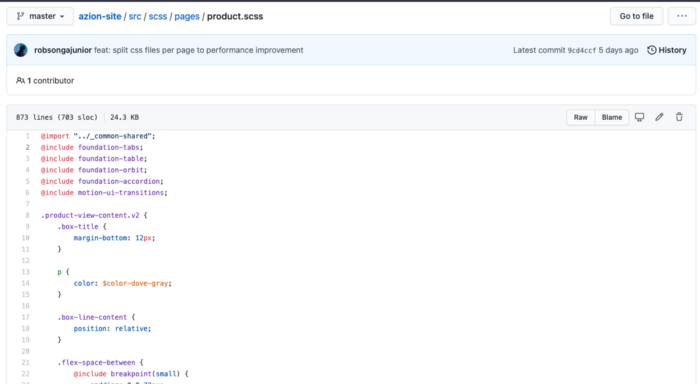
Assim, uma página com maior número de componentes ficou com tamanho aproximado de 90k depois de ser compilada.
Integrando com o HTML
Quem usa ferramentas de SSG e está acostumado a configurar Front-Matters tem esse tipo de marcação no topo do arquivo para mostrar como o conteúdo deve ser compilado.
Com isso, fizemos apenas pequenas mudanças nas nossas páginas.
Passamos de um header nas páginas HTML que continham todo o necessário, como mostrado a seguir:

Para:

Agora, esse estilo virá da configuração do Front-Matter atualizado durante o build. Seria algo como:
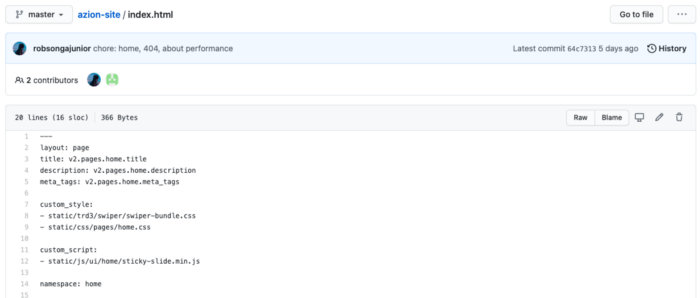
Podemos ver que utilizamos o máximo dos recursos já utilizados com alterações sutis, o que acaba nos proporcionando ganhos enormes.
Quais foram os nossos resultados?
No fim desse processo, observamos que tivemos mais de 70% de melhoria em:
- LCP: de 2.1s para 1.3s;
- First Byte: 0.256s para 0.18s;;
- Start Render: de 1.9s para 0.6s;
- First Contentful Paint: de 1.8s para 0.63s;
- Speed Index: de 2s para 0.7s;
Tudo isso indica, portanto, que a importância da arquitetura JAMStack está cada vez mais consolidada.





