Uma região: Global
- Ashburn
- Atlanta
- Chicago
- Dallas
- Denver
- Los Angeles
- Miami
- Nova Iorque
- Phoenix
- São José
- Seattle
- Querétaro
Hiperconexão através de números
para alcançar qualquer lugar nas Américas e na Europa
ASNs diretamente conectados à rede da Azion
disponibilidade garantida por SLA
Locais de borda ao redor do mundo
A estratégia de conectividade robusta da Azion nos ajuda a oferecer o melhor desempenho, disponibilidade e resiliência aos nossos clientes.
Nossa arquitetura altamente distribuída inclui edge nodes estrategicamente localizados dentro das redes de última milha dos ISPs (Provedores de Serviços de Internet) e conectividade com múltiplos PTTs (Pontos de Troca de Tráfego), peerings privados e públicos, e provedores de trânsito de Tier 1 ao redor do mundo.
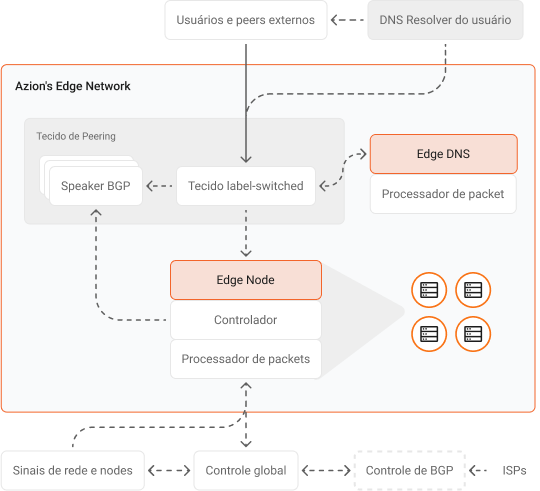
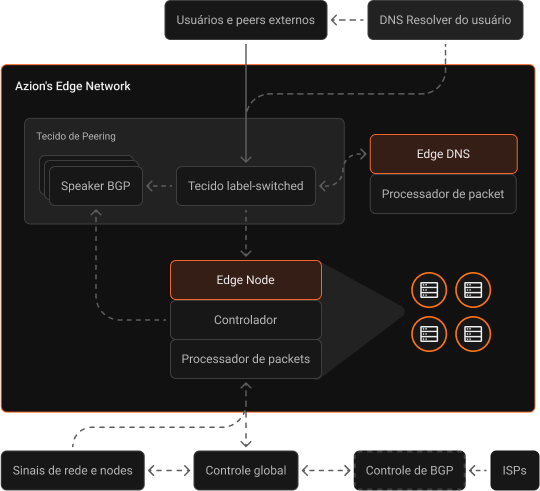
A rede possui defesa DDoS em cada edge location e se conecta a vários centros de mitigação em todo o mundo, garantindo total confiabilidade e sem afetar o desempenho.
A missão de criar uma internet mais segura e confiável é, para nós, um valor fundamental. Para promovê-la ainda mais, também colaboramos, ao lado de outros atores do mercado, com a iniciativa MANRS (Mutually Agreed Norms for Routing Security), da Internet Society.


Live Map da Azion
Descubra o comportamento do e-commerce em tempo real, os horários com mais tráfego e as regiões com o maior número de ataques bloqueados.
Cadastre-se e ganhe US$300 para usar por 12 meses.
Acesso a todos os produtos
Não é necessário cartão de crédito
Crédito disponível para uso durante 12 meses